
household energy consumption编程代做
This Assignment is worth 35% of the final module mark.
The challenge
Accurately predicting household energy consumption allows local power distribution companies to better forecast energy trends and perform demand management1. Power system demand management has gained heightened importance as the world transitions towards renewable energy2. The rhetoric of the UK aiming to become “the Saudi Arabia of wind”3 with the emergence of wind farms in the North Sea4 has seen the nation pivot away from conventional fossil fuels towards cleaner, more sustainable sources. The North Sea's wind farms furnish a bountiful but highly variable power supply for UK households, providing a path towards national energy independence by reducing reliance on the importation of fossil fuels. Nevertheless, the primary technical hurdles hindering the increased adoption of wind energy in the UK revolve around efficiently transmitting power over long distances from the North Sea to urban centres5, coupled with the challenge of seamlessly meeting demand during periods of low wind energy production or increased household energy use. In this project, we aim to address a component of these challenges by constructing a predictive model for household energy demand. Our client, the national grid, may then use our model to help forecast when alternative energy production facilities need to be ramped up to meet household energy demands.
This coursework aims to create an effective machine-learning workflow for predicting household energy data. Your assigned tasks, detailed on the following page, require you to devise solutions independently. Alongside demonstrating your data modelling abilities, this assignment evaluates your professional engineering skills, including adherence to specifications, delivering tested and commented code, meeting client requirements, and justifying your approach.
Deliverables
1. A report as a single PDF file;
2. Code submitted as a single .zip file.
Data available
You have been granted access to the 'household_energy_data.csv' dataset, comprising 50,392 entries. The first row contains the names of each feature variable, while the subsequent 50,391 rows contain the corresponding data points associated with each household snapshot. These data snapshots capture household energy demands, smart meter readings of diverse household appliances, and concurrent weather conditions. The dataset consists of 30 columns, each representing distinct features. The first column is entitled “EnergyRequestedFromGrid_kW_” and this is the variable we are trying to predict.
1 Ndiaye, Demba. et al. "Principal component analysis of the electricity consumption in residential dwellings." Energy and buildings 43.2-3 (2011): 446-453.
2 Jones, Morgan. et al. "Solving dynamic programming with supremum terms in the objective and application to optimal battery scheduling for electricity consumers subject to demand charges." 2017 3 Bamisile, Olusola, et al. "Enabling the UK to become the Saudi Arabia of wind? The cost of green hydrogen from offshore wind."
4 Potisomporn, Panit, and Christopher R. Vogel. "Spatial and temporal variability characteristics of offshore wind energy in the United Kingdom." Wind Energy 25.3 (2022): 537-552.
5 Cullinane, Margaret, et al. "Subsea superconductors: The future of offshore renewable energy transmission?." Renewable and Sustainable Energy Reviews 156 (2022): 111943.
Task/Assessment Description and Marks Available Task
Task 0: Provide well-commented code that could plausibly reproduce all results shown in the report. The code should have a main run file within the zip folder (see the following page for more details) with comments on what the code does and which toolboxes are required for the code to run.
Marks available
10
30
Task 2. Build a linear regression model to predict household energy consumption
based on your processed data set from Task 1. Discuss implementation and
technical issues such as collinearity in the report. Provide plots and metrics to 20 assess the quality of your model.
Task 3. Build a second model (for example a high-order polynomial, an ANN or
even a technique we have not seen in class). Detail how overfitting to the data set
was mitigated. Discuss implementation and technical issues in the report.
Compare the results with the linear regression model from Task 2 and justify 40 which model is the better model. Summarize the report by articulating the
motivation, ethical issues and future challenges in machine learning and AI technologies in the context of this project.
Penalties
Incorrect report/code layout (for layout see following page) -5% Wrong file type -5% Exceeded page limit -5% Late submission
Task 1: Conduct data cleaning. This could involve deciding which features to drop and which relevant features to keep, how to scale, pre-process, bound the data, etc. It could also involve a discussion about which features are most important to this specific prediction task, taking into consideration information and domain-specific knowledge other than the provided data set. Clearly discuss in the report what data cleaning was done and the reasons for doing this.
Variable
Technical Report and Code.
Report
• You are permitted a maximum of five A4 sides of 11 point type and 25mm margins.
Any references, plots and figures must be included within these five pages. Don’t waste space on cover pages or tables of contents. If you exceed the limit you will be penalised and content not within the 5-page limit will not be marked.
• You must save your document as a pdf file only - no other format is acceptable.
• Your report should consist of three sections corresponding to Tasks 1,2 & 3.
Code
Your code must run standalone, in other words, when testing we will clear the workspace and load your code. Any function you created should be included in the .ZIP file. Do not include the data in your submission. Your code should work with the dataset provided, in the shape and format it was provided, which is available to the staff marking your work. Should the data require any pre-processing, this should be done within your code. Already pre-processed data or any dataset different from the one provided will be discarded if found in your submission.
Within the .ZIP file there should be a script named “main_run”, this is the file we will run, and it should generate all the results from the report. At the beginning of the “main_run”, you should follow standard programming conventions and provide comments concerning the implementation details including details of any external toolboxes required.
This assignment is designed to be done in MATLAB, however, should you find yourself more comfortable using Python, you are free to use it. You are also free to use toolboxes/libraries but must detail their use in the comments in the “main_run” file.
Extenuating Circumstances: If you have any extenuating circumstances (medical or other special circumstances) that might have affected your performance on the assignment, please get in touch with the student support office (lecturers are righteously kept outside the process) and complete an extenuating circumstances form. Late submission rules apply with a reduction in 5% for every additional late day and a score of zero after 5 days.
.请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- 木秋水·好眼光——繁花爱眼综合解决方案,为眼养护领域给出“东方答案”
- Ins群发脚本助手,Instagram一键群发工具,让你打造营销新格局!
- 跨境电商 Line 群发云控 虚拟商城的幻境
- 三农服务一站集成,“超级码合格证智能应用一体机”重磅面世,开创三农智能化的无限可能!
- 德国年轻化保健品牌,Allessenz爱乐生领跑胶原新技术
- WhatsApp群发协议软件/ws拉群助手/ws协议号
- 揭秘义乌市友久贸易有限公司四川分公司用心塑造形象,去迎合消费群
- 木心集团与复旦大学“奖学金”颁奖暨“实习基地”揭牌仪式,圆满举行!
- 当我遭遇低谷时 这个WhatsApp拉群营销工具让我找回了对事业的激情和信心
- 全方位Telegram代群发,从梦想到现实,通过Telegram工具实现了生意的喜悦变现
- WhatsApp群发软件,ws全球代发/ws拉群/ws接粉/ws协议号出售
- Alpha律所管理系统,助力律师团队管理提效再升级
- 外贸踏实记 我用WhatsApp拉群营销工具 业务实现了突破性增长
- ins群发营销软件,ins营销软件,协议操作自动发送日日爆粉
- Ins引流推广软件,Instagram采集器一键助你博主打粉成功!
- Ins高效筛选助手,Instagram群发代发工具,让你的营销更高效!
- Telegram定位采集营销助手,TG全球坐标定位采集软件,电报群组坐标采集利器
- TPS2051BDG4: Precision Power Distribution Switch for Electronic Systems | ChipsX
- 转化巅峰 喜悦飞扬 WhatsApp拉群工具为你的销售数字添彩夺目
- 代做COMP9021、代写Python设计编程
- WhatsApp群发/ws劫持号/ws协议号/ws拉群/WS全业务咨询
- 成功博主分享 WhatsApp拉群营销工具的魔力 让业务成果显著提升
- 专业人士请教 WhatsApp拉群营销工具的使用经验 有人愿意分享吗
- ins群发软件,ins营销工具,海外爆粉工具能带来什么帮助?
- 年度新品:Fit.Q有机生酮咖啡,高效燃脂健康瘦!
- Instagram营销软件 - ins采集软件/ig采集助手/ins群发助手/一键引流
- 智慧医疗时代,两位院士、百余位学科带头人在如何做健康管理?
- Instagram营销群发工具,ins私信采集软件/ig博主采集神器/测试联系大轩
- 饮食设备:打造美食世界的秘密武器
- 智能合约的滑稽契约:参与一场智能合约的滑稽跨境电商 WhatsApp 群发云控笑话,别错过这场科技盛宴
推荐
-
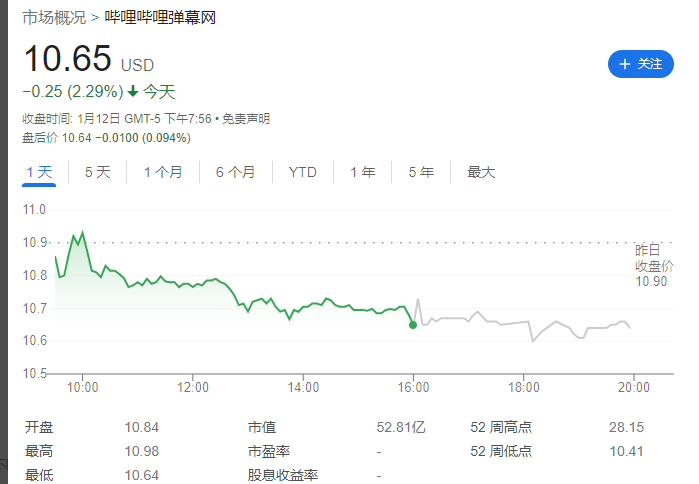 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
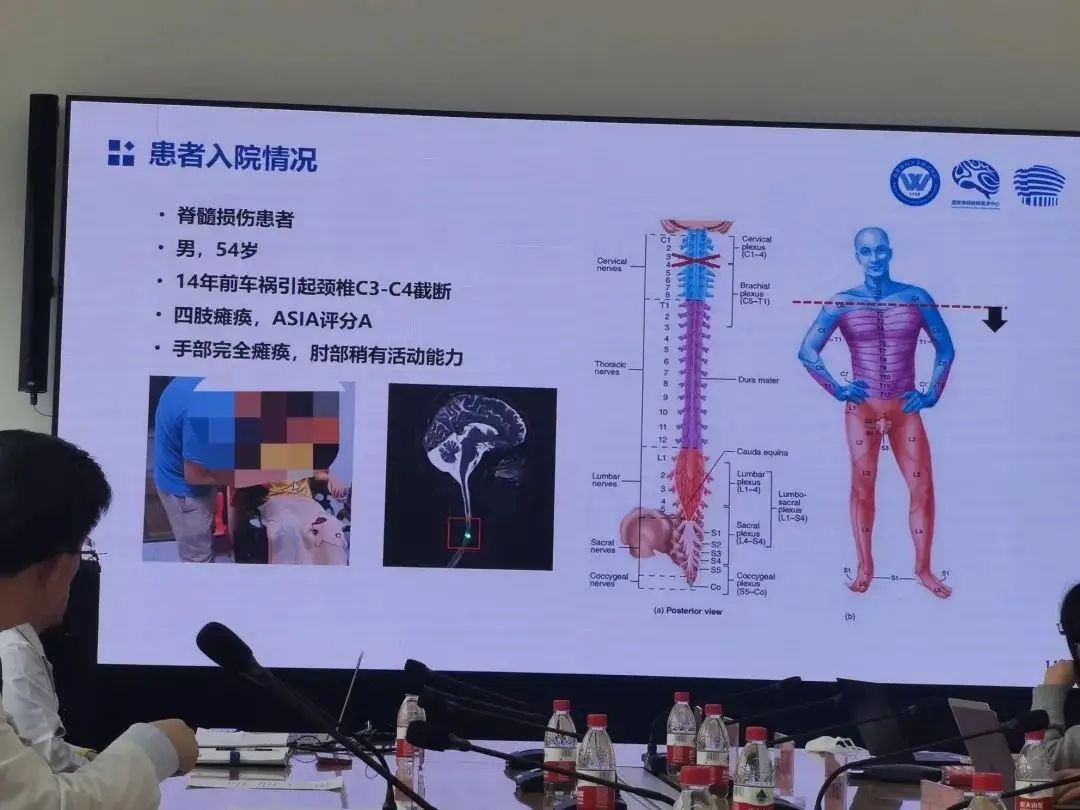 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技