
代做COMP3211、Python/Java程序代写
Coursework Specification
Late submissions will be penalised at 10% per working day.
No work can be accepted after feedback has been given.
You should expect to spend up to 37.5 hours on this assignment.
Please note the University regulations regarding academic integrity.
Module: COMP3211 Advanced Databases
Assignment: Database Programming Exercise Weighting: 25 %
Deadline: 16:00 Wed 8 May 2024 Feedback: Fri 17 May 2024
Instructions
In this assignment, you will build a query optimiser for SJDB, a simple RDBMS. Your optimiser should accept a
canonical query plan (a project over a series of selects over a cartesian product over the input named
relations) and aim to construct a left-deep query plan which minimises the sizes of any intermediate relations.
Part 1: Estimator.java
Before implementing an optimiser for query plans, you must first estimate the cost of the query plans.
In the first phase, you must create a class Estimator that implements the PlanVisitor interface and performs
a depth-first traversal of the query plan. On each operator, the Estimator should create an instance of Relation
(bearing appropriate Attribute instances and tuple counts) and attach to the operator as its output.
Some operators may require you to revise the value counts for the attributes on the newly created output
relations (for example, a select of the form attr=val will change the number of distinct values for that
attribute to 1). Note also that an attribute on a relation may not have more distinct values than there are
tuples in the relation.
Page 5 of this coursework specification lists the formulae that you should use to calculate the sizes of the
output relations, and to revise the attribute value counts. The supplied distribution of SJDB includes a
skeleton for Estimator, including an implementation of the visit(Scan) method.
Part 2: Optimiser.java
Once you have an estimator, you must create a class Optimiser that will take a canonical query plan as input,
and produce an optimised query plan as output. The optimised plan should not share any operators with the
canonical query plan; all operators should be created afresh.
In order to demonstrate your optimiser, you should be able to show your cost estimation and query
optimisation classes in action on a variety of inputs. The SJDB zip file contains a sample catalogue and
queries. In addition, the SJDB class (see page 3) contains a main() method with sample code for reading a
serialised catalogue from file and a query from stdin.
Part 3: Report
In addition to your estimator and optimiser, you should produce a short (maximum 500 word) report that
describes the optimisation strategy that you’ve adopted.
Note
You should not need to modify any of the provided classes or interfaces as part of your submission (aside
from Estimator), but if you think that you have a justifiable reason for doing so, please contact Nick for
permission first.
2
Submission
Please submit your files (Estimator.java, Optimiser.java and report.pdf) using the electronic hand-in system
(http://handin.ecs.soton.ac.uk/) by 4pm on the due date.
Late submissions will be penalised at 10% per working day and no work can be accepted after feedback has
been given.
You should expect to spend up to 37.5 hours on this assignment, and you should note the University
regulations regarding academic integrity:
http://www.calendar.soton.ac.uk/sectionIV/academic-integrity-statement.html
Relevant Learning Outcomes
1. The internals of a database management system
2. The issues involved in developing database management software
3. Demonstrate how a DBMS processes, optimises and executes a query
4. Implement components of a DBMS
Marking Scheme
Criterion Description Outcomes Total
Cost Estimator Implementation of the cost estimator 1,2,3,4 40 %
Optimiser Implementation of the query optimiser 1,2,3,4 40 %
Report Description of your query optimisation strategy 1,2,3 20 %
Note that partial credit will be given for incomplete solutions; for example, an optimiser that moves some
(but not all) selections down the query plan will still receive part of the total mark for the optimiser
component.
3
SJDB – A Simple Java Database
SJDB supports a limited subset of the relational algebra, consisting of the following operators only:
• cartesian product
• select with a predicate of the form attr=val or attr=attr
• project
• equijoin with a predicate of the form attr=attr
• scan (an operator that reads a named relation as a source for a query plan)
In addition, all attributes on all relations will be strings; there are no other datatypes available. Attributes also
have globally unique names (there may not be two attributes of the same name on different relations), and
self-joins on relations are not permitted.
The sjdb package contains the following classes and interfaces:
Relation an unnamed relation, contains attributes
NamedRelation a named relation
Attribute an attribute on a relation
Predicate a predicate for use with a join or select operator
Operator abstract superclass for all operators
UnaryOperator abstract superclass for all operators with a single child
Scan an operator that feeds a named relation into a query plan
Select an operator that selects certain tuples in its input, via some predicate
Project an operator that projects certain attributes from its input
BinaryOperator abstract superclass for all operator with two children
Product an operator that performs a cartesian product over its inputs
Join an operator that joins its inputs, via some predicate
Catalogue a directory and factory for named relations and their attributes
CatalogueException a failure to retrieve relations or attributes from the catalogue
CatalogueParser a utility class that reads a serialised catalogue from file
QueryParser a utility class that reads a query and builds a canonical query plan
PlanVisitor an interface that when implemented performs a depth-first plan traversal
Inspector a utility class that traverses an annotated plan and prints out the estimates
SJDB class containing main()
Test an example of the test harnesses used for marking
The SJDB class contains a main() method with skeleton code for reading catalogues and queries.
The system provides basic statistical information about the relations and attributes in the database, as below.
These are stored on the relations and attributes themselves, and not in the catalogue.
• the number of tuples in each relation
• the value count (number of distinct values) for each attribute
A sample serialised catalogue (cat.txt) and queries (q1.txt, etc) are available in sjdb/data.
4
Test Harness Notes
The file Test.java in the SJDB distribution contains an example of the test harness that I will be using to mark
your submissions. This example test harness manually constructs both plans and catalogues as follows:
package sjdb;
import java.io.*;
import java.util.ArrayList;
import sjdb.DatabaseException;
public class Test {
private Catalogue catalogue;
public Test() {
}
public static void main(String[] args) throws Exception {
Catalogue catalogue = createCatalogue();
Inspector inspector = new Inspector();
Estimator estimator = new Estimator();
Operator plan = query(catalogue);
plan.accept(estimator);
plan.accept(inspector);
Optimiser optimiser = new Optimiser(catalogue);
Operator planopt = optimiser.optimise(plan);
planopt.accept(estimator);
planopt.accept(inspector);
}
public static Catalogue createCatalogue() {
Catalogue cat = new Catalogue();
cat.createRelation("A", 100);
cat.createAttribute("A", "a1", 100);
cat.createAttribute("A", "a2", 15);
cat.createRelation("B", 150);
cat.createAttribute("B", "b1", 150);
cat.createAttribute("B", "b2", 100);
cat.createAttribute("B", "b3", 5);
return cat;
}
public static Operator query(Catalogue cat) throws Exception {
Scan a = new Scan(cat.getRelation("A"));
Scan b = new Scan(cat.getRelation("B"));
Product p1 = new Product(a, b);
Select s1 = new Select(p1, new Predicate(new Attribute("a2"), new Attribute("b3")));
ArrayList<Attribute> atts = new ArrayList<Attribute>();
atts.add(new Attribute("a2"));
atts.add(new Attribute("b1"));
Project plan = new Project(s1, atts);
return plan;
}
}
As can be seen in this test harness, I use the Inspector class (provided with the SJDB sources) to print out a
human-readable version of your query plans – your query plans must be able to accept this visitor without
throwing exceptions. Your estimator and optimiser need not (and should not) produce any data on stdout
(you should use the Inspector for this when testing).
Note also that you should manually construct plans that contain joins in order to test your Estimators.
Estimators and Optimisers that do not run without errors will be marked by inspection only, and will
consequently receive a reduced mark.
5
Cost Estimation
As described in lectures, the following parameters are used to estimate the size of intermediate relations:
• T(R), the number of tuples of relation R
• V(R,A), the value count for attribute A of relation R (the number of distinct values of A)
Note that, for any relation R, V(R, A) ≤ T(R) for all attributes A on R.
Scan
T(R) (the same number of tuples as in the NamedRelation being scanned)
Product
T(R × S) = T(R)T(S)
Projection
T(πA(R)) = T(R) (assume that projection does not eliminate duplicate tuples)
Selection
For predicates of the form attr=val:
T(σA=c(R)) = T(R)/V(R,A), V(σA=c(R),A) = 1
For predicates of the form attr=attr:
T(σA=B(R)) = T(R)/max(V(R,A),V(R,B)), V(σA=B(R),A) = V(σA=B(R),B) = min(V(R,A), V(R,B)
Join
T(R⨝A=BS) = T(R)T(S)/max(V(R,A),V(S,B)), V(R⨝A=BS,A) = V(R⨝A=BS,B) = min(V(R,A), V(S,B))
(assume that A is an attribute of R and B is an attribute of S)
Note that, for an attribute C of R that is not a join attribute, V(R⨝A=BS,C) = V(R,C)
(similarly for an attribute of S that is not a join attribute)
Further Reading
For further information on cost estimation, see §16.4 of Database Systems: The Complete Book
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- 国家重点研发计划“儿童罕见病诊断关键技术与治疗靶点发现及转化医学研究”项目启动
- 在国际市场 没有WhatsApp拉群工具 就像是无剑之侠 这是每位海外营销专家的绝对利器
- 群发大数据时代,挑战创意极限:LINE营销工具助你创造推广的独特风格Line群发云控让您的推广更具针对性
- 营销新时代,选择 WhatsApp群发协议号轻松推广!让您的品牌消息脱颖而出!
- 电报/TG高效群发软件,Telegram/TG群发助手,TG/纸飞机营销策略优化
- Ins引流工具,Instagram营销软件,助你实现市场吸粉领先!
- Instagram打粉营销软件,Ins引流助手,共同助你赢得市场!
- 世贸通美国投资EB-5移民:谁不想投资这样一个EB5项目?
- 网络通信新标杆:WhatsApp协议号推广引领未来!
- 魔方网表,私有部署的excel共享方案
- WhatsApp拉群可以帮你海外市场实现了营销的巨大突破,从此站上了事业的巅峰
- Instagram批量养号 - ins自动登录/ig采集指定地区/ins群发软件/ig群发工具
- WhatsApp群发云控软件,ws协议云控功能/ws协议号批发
- 田中贵金属工业确立了使用“预成型AuRoFUSE(TM)”的半导体高密度封装用接合技术
- Yeelight易来与蜂巢、峰米等品牌达成合作,携手开拓智能家居市场
- WhatsApp群发软件,ws/WhatsApp营销策略/ws协议号销售点/ws筛选工具
- 代写COMP9021 Principles of Programming
- 代写Stochastic Processes、代做Python设计编程
- Telegram拉群软件,实现品牌精准推广
- 全球智慧 专家分享 WhatsApp拉群营销工具点燃我业务成功的烈火
- 群发智能升级 专业海外营销者分享 WhatsApp拉群工具如何应对风控挑战 提升业务成绩
- 代做ICS4U、代写 java 程序语言
- Instagram群发筛选软件,Ins群发注册工具,助你轻松推广!
- 未知之域 科技魔法师迷茫 WhatsApp拉群营销工具是否是数字时空的穿越者
- 陈丹感恩:恒兴33年,感恩一路有你
- Ins群发脚本助手,Instagram一键群发工具,让你打造营销新格局!
- Instagram自动采集神器,ins全球采集软件,ig营销软件
- Telegram引流利器,智能群发采集,助你快速引流!
- 世贸通美国移民:EB5乡村项目I-956F已获批,I-526E获批需多久?
- 西部数据蝉联六年ETHISPHERE“全球最具商业道德企业”
推荐
-
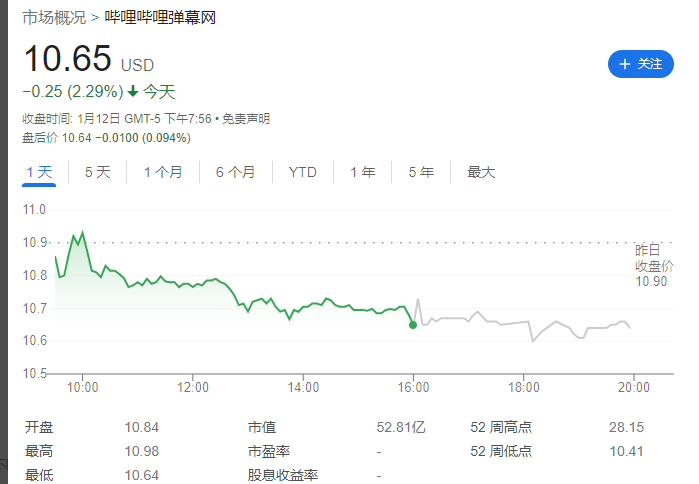 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
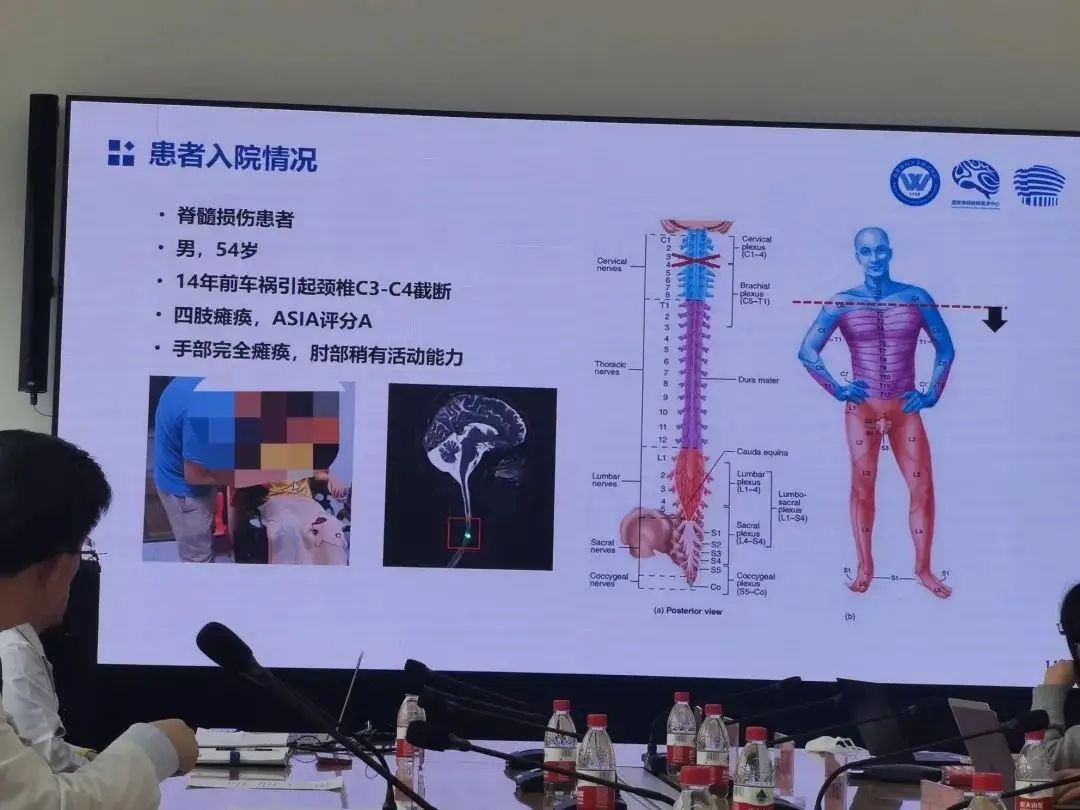 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技