
代做ESTR2520、Python程序设计代写
FTEC2101/ESTR2520 Optimization Methods Spring 2024
Project Specification – Binary Classification for Bankruptcy Detection
Last Updated: April 4, 2024, Deadline: May 10, 2024, 23:59 (HKT)
Thus far we have learnt a number of optimization methods, ranging from the simplex method for linear
programming, modeling techniques for integer programming, gradient/Newton methods for unconstrained
optimization, KKT conditions, SOCP formulation, etc.. Besides theories, please remember that optimization
methods are practical tools for solving real world problems. The aim of this project is to practice our skill on
the latter aspect. We will make use of the Julia1
environment.
The project’s theme is about practical solutions for binary classification. It can be considered as an extension to
what we have experimented in Computing Lab 2. We will explore additional aspects about binary classification
and more importantly, implement and compare these ideas on a real-world dataset.
Background. Let us recall that the binary classification task aims at learning a linear classifier that distinguishes a feature vector as positive (+1) or negative (−1). Let d ∈ N be the dimension of the feature vector,
the (linear) classifier is described by the tuple (w, b) where w ∈ R
d
is the direction parameters and b ∈ R is
the bias parameter2
, both specifying the linear model. Given (w, b), a feature vector x ∈ R
d
is classified into
a label y ∈ {±1} such that
y =
(
+1, if w⊤x + b = w1x1 + · · · + wdxd + b ≥ 0,
−1, if w⊤x + b = w1x1 + · · · + wdxd + b < 0.
(1.1)
As an illustration, the following figure shows a case with d = 2 such that the classifier is described by
w = (w1, w2) and the scalar b:
Fig. 1. Example dataset.
According to the rule in (1.1), all the feature vectors that lie above the dashed line shall be classified as +1
(blue points); those that lie below the dashed line shall be classified as −1 (red points).
1As an alternative, you are welcomed to use Python with optimization modeling packages supporting SOCP and MI-NLP such
as cvxpy. However, you have to notify the instructor about the choice and the plan on how you wish to accomplish the project
in the latter case on or before May 1, 2024, i.e., two weeks before the deadline. In the project, you are not allowed to use any
pre-built solver for binary classification such as MLJ.jl, ScikitLearn.jl, flux.jl, scikit-learn in your final submission (though
you are encouraged to try out these packages as extra work to support your solution). Please ask the instructor if you are unsure
whether a specific package can be used.
2Note that this differs slightly from Lecture 16 as we include the bias parameter in the classifier design.
1
FTEC2101/ESTR2520 Project 2
Dataset & Folder Setting We have m ∈ N samples of training data described by {x
(i)
, y(i)}
m
i=1, where
x
(i) ∈ R
d
is the ith feature vector and y
(i) ∈ {±1} is the associated label. We will use a curated version
of the Bankruptcy dataset taken from https://archive.ics.uci.edu/dataset/365/polish+companies+
bankruptcy+data. It includes the d = 64 performance indicators from around 10000 companies in Poland
from 2000 to 2012, and includes a label that tells if the company has gone bankrupt or not. Our goal is to
learn a classifier to predicts if a company is going to bankrupt based on its recent performance.
To prepare the environment for the project, retrieve the Jupyter notebook ftec2101-project-2024.ipynb
and the zip archive ftec-project-files.zip from Blackboard. Place the *.ipynb files in a working directory,
extract the *.zip file and move the *.csv files inside the same working directory. Your working directory
should have the following content:
Notice that:
• ftec-groupi-train.csv – the training dataset for students in group i, i = 1, 2, 3, 4, 5, 6. This is a csv
file that contains 20 samples of company data to be used in the Compulsory Tasks.
• ftec-groupi-test.csv – the testing dataset for students in group i, i = 1, 2, 3, 4, 5, 6. This is a csv file
that contains 60 samples of company data to be used in the Compulsory Tasks.
• ftec-full-train.csv – the training dataset that contains 8000 samples of company data to be used in
the Competitive Tasks.
• ftec-full-test.csv – the training dataset that contains 2091 samples of company data to be used in
the Competitive Tasks.
Lastly, the Jupyter notebook ftec2101-project-2024.ipynb provided detailed descriptions and helper codes
to guide you through the tasks required by this project. Please pay attention to the comments provided inside
the code cells of the Jupyter notebook as well.
1.1 Compulsory Tasks (50% + 2% Bonus)
The compulsory tasks of this project is divided into two parts. You are required to
(A) answer questions related to the optimization theory and modeling related to binary classification; and
(B) implement the modeled optimization problems on computer and solve them with the Bankruptcy dataset.
FTEC2101/ESTR2520 Project 3
Theory and Modeling Denote the training dataset with m samples as {x
(i)
, y(i)}
m
i=1, where x
(i) ∈ R
d
is the ith feature vector with d attributes and y
(i) ∈ {±1} is the associated label. Let R0 > 0 and ℓi > 0,
i = 1, ..., m be a set of positive weights. The following optimization problem designs a soft-margin classifier :
min
w∈Rd,b∈R
Xm
i=1
ℓi max{0, 1 − y
(i)
(x
(i)
)
⊤w + b
} s.t. w⊤w ≤ R0. (1.2)
It can be easily shown that (1.2) is a convex optimization problem.
Task 1: Formulation (10% + 2% Bonus)
Answer the following question:
(a) Suppose that the optimal objective value of (1.2) is zero. Explain why in this case, with reference
to (1.1), any optimal solution to (1.2) is a classifier (w⋆
, b⋆
) that can correctly distinguish the m
training samples into the +1 or −1 labels.
(b) Give an example of training dataset with d = 2 where the optimal objective value of (1.2) is not
zero. You may describe such dataset by drawing it on a 2-D plane.
(c) Rewrite (1.2) as an equivalent nonlinear program like the form given in the lecture notes, e.g.,
min f0(x) s.t. fi(x) ≤ 0, i = 1, ..., m. Make sure that each of the fi(x) is differentiable.
(d) Derive the KKT condition for the equivalent formulation in (c).
(e) Suppose the optimal objective value of (1.2) is zero, show that there may exist more than one
optimal solution to (1.2). (Hint: you may let d = 2 and consider a similar dataset to the one
illustrated in Fig. 1).
(f) (Bonus) Explain the phenomena in (e) using the KKT conditions derived in (d).
Eq. (1.2) is called the soft-margin formulation for binary classification. In particular, we observe that the term
max{0, 1 − y
(i)
(x
(i)
)
⊤w + b
} evaluates the amount of error for the ith sample, and we note that the term is
> 0 if and only if the ith training sample is mis-classified for the sample, i.e., y
(i)
(x
(i)
)
⊤w + b
≱ 1.
Feature/Attribute Selection. Besides the (training) accuracy of a model, for classification problem with
large d, i.e., there are many attributes, another interesting aspect is on the set of selected attributes. Let
w⋆ ∈ R
d be an optimal classifier, e.g., found by solving (1.2), the selected attributes are
S := {i ∈ {1, . . . , d} : |w
⋆
i
| ̸= 0}
An attribute j is not selected if w
⋆
j = 0 as it does not contribute to the prediction of label in (1.1).
In practice, it is believed that a sparse classifier, i.e., one with a small |S|, is better as it is easier to interpret,
easier to implement, etc. In the following tasks, we will build upon the model (1.2) and incorporate various
constraints to favor a sparse classifier design into the classifier design (via optimizatio
FTEC2101/ESTR2520 Project 4
Task 2: Optimization Formulation (10%)
Answer the following questions:
(a) Show that (1.2) can be written as a Second-order Cone Programming (SOCP) problem.
(b) We now incorporate a shaping constraint into the soft-margin problem. Formulate a similar SOCP
problem to the one in part (a) with the following requirement: for given R0, R1 > 0,
• The objective is the same as in (1.2).
• The directional parameters w ∈ R
d
satisfies the following shaping constraint:
w⊤Σw + c
⊤w ≤ R0,
where Σ ∈ R
d×d
is a given symmetric, positive definite matrix, and c ∈ R
d
is a given vector.
• The directional parameter and bias parameter belongs to an ℓ1 ball to promote sparsity, i.e.,
X
d
i=1
|wi
| + |b| ≤ R1.
You may begin by formulating the problem as specified above, and then demonstrate how the
problem can be converted into an SOCP.
(c) As an alternative to part (b), formulate a mixed integer program (MIP) problem which imposes
a hard constraint on the sparsity of the classifier, i.e., for given R0 > 0, R1 > 0, S > 0, specified as
• The objective is the same as in (1.2).
• The directional parameters w ∈ R
d
satisfies the following shaping constraint:
w⊤Σw + c
⊤w ≤ R0,
where Σ ∈ R
d×d
is a given symmetric, positive definite matrix, and c ∈ R
d
is a given vector.
• Each element in w is bounded such that
−R1 ≤ wi ≤ R1, i = 1, ..., d.
• The number of non-zero elements in the vector w is constrained such that
(no. of non-zero elements in the vector w) ≤ S
Computational We shall put the optimization designs formulated in the above into practice. Our
tasks are structured into 3 stages: data analysis, optimization, interpretation. The Jupyter notebook template
ftec2101-project-2024.ipynb provides descriptions and helper codes to guide you through most of the
following tasks. Please pay attention to the comments in the Jupyter notebook.
In the compulsory tasks, we focus on a training dataset of m = 20 companies (ftec-groupi-train.csv). Each
company has 64 attributes (performance indicators). The dataset also contains information of whether the
company has bankrupted or not, treated as the label yi ∈ {±1}.
FTEC2101/ESTR2520 Project 5
Task 3: Warmup Exercise (5%)
(a) Inspect the dataset by making a 2-D scatter plots of the 20 samples over the features ‘Attr1’ and
‘Attr2’ that corresponds to ‘net profit / total assets’ and ‘total liabilities / total assets’, respectively.
Mark the ‘Bankrupt’ (resp. ‘Not Bankrupt’) companies in red (resp. blue). Comment on the pattern
observed.
(b) Try 2-3 more combinations of pairs of features and make comments on the observations.
Remark: The program template has provided the relevant helper codes for this task, but you may have
to ‘tweak’ the template to examine other pairs of features in part (b).
For part (a) in the above, you may observe an output similar to:
Moreover, you may notice that the training dataset is unbalanced. There are only 15-20% of bankrupted
companies with a +1 label. In the following tasks, you will implement classifier designs based on the MIP and
SOCPs from Task 2.
As a first step, we design the classifier based on the first d = 10 features, i.e., ‘Attr1’ to ‘Attr10’.
FTEC2101/ESTR2520 Project 6
Task 4: Optimization-based Formulation (15%)
(a) Implement and solve the SOCP problem from Task 2-(a) with the following parameters:
ℓi = weight · (yi + 1) + 1, R0 = 5.
Note that weight > 0 is a given scalar that you can modify in the Jupyter notebook. In particular,
it serves the purpose of weighing more for the samples with bankrupted companies. You may use
the solver ECOS in JuMP for the SOCP.
(b) Implement and solve the SOCP problem from Task 2-(b) with the following parameters:
ℓi = weight · (yi + 1) + 1, R0 = 5, R1 = 2.5, c = 0, Σ = I.
You may use the solver ECOS in JuMP for the SOCP.
(c) Implement and solve the MIP problem from Task 2-(c) with the following parameters:
ℓi = weight · (yi + 1) + 1, R0 = 5, R1 = 10, S = 2, c = 0, Σ = I.
You may use the solver Juniper in JuMP for the MIP.
(d) Using the default setting of weight = 1 for the above. Compare the sparsity level of the classifier
solutions found in part (a), (b), (c) by plotting the values of the classifiers learnt. Comment on
whether the classifiers found are reasonable.
Notice that it may take a while to solve the MI-NLP in Task 5-(c) since an MIP problem is quite challenging
to solve in general (with d = 10, in the worst case, it may have to test 210 options).
Recalling from Computing Lab 2, the performance of a classifier can be evaluated by the error rate when
applied on a certain set of data. It can further be specified into false alarm rate and missed detection rate. To
describe these metrics, note that for a given classifier (w, b), the predicted label is
yˆ
(i) =
(
+1, if w⊤x
(i) + b ≥ 0,
−1, if w⊤x
(i) + b < 0,
Now, with the training dataset {x
(i)
, y(i)}
m
i=1. Suppose that m− is the number of samples with yi = −1 and
D− is the corresponding set of samples, m+ is the number of samples with yi = 1 and D+ is the corresponding
set of samples. The error rates are
False Alarm (FA) Rate = 1
m−
X
i∈D−
1(ˆy
(i)
̸= −1), Missed Detection (MD) Rate = 1
m+
X
i∈D+
1(ˆy
(i)
̸= 1) (1.3)
Notice that both error rates are between 0 and 1. Sometimes they are called the Type I and Type II errors,
respectively, see https://en.wikipedia.org/wiki/False_positives_and_false_negatives.
As our aim is to design a classifier that makes prediction on whether a future company that is not found in the
training dataset will go bankrupt, it is necessary to evaluate the error rate on a testing dataset that is unseen
during the training. Denote the testing dataset with mtest samples as {x
(i)
test, y
(i)
test}
mtest
i=1 , the testing error rate
for a classifier (w, b) can be estimated using similar formulas as in (1.3). Consider the following task:
FTEC2101/ESTR2520 Project 7
Task 5: Error Performance (10%)
For our project, the testing dataset is prepared in ftec-groupi-test.csv.
(a) Write a function fine error rate that evaluates the FA/MD error rates as defined in (1.3).
(b) Evaluate and compare the error rate performances for the 3 formulations you have found in Task
4. For each of the formulation, adjust the parameter weight≥ 0 so that it balances between the
FA and MD rates on the training dataset, e.g., both rates are less than or equal 0.5. (The weight
parameter can be chosen individually for each classifier formulation, you may try anything from 0.5
to 2 until you get the desired performance).
(c) Based on the fine tuned classifiers in part (b), find the top-2 most significant features selected by
the optimization from the MIP formulation. Then, make a scatter plot (similar to Task 3-(a)) of
the training dataset for the two selected features. Then, overlay the fine tuned classifiers found
in part (b) on top of this scatter plot while ignoring other features.
Remark: Please make the function for evaluating error in (a) general such that it takes dataset of any size
and features of any dimension. You will have to reuse the same function in Task 6. For part (c), please
refer to (1.1) how you would define a line on the 2D-plane of the selected attributes, and pay attention to
the comment provided in the helper code.
The scatter plot in Task 5-(c) may look like (the selected attributes may vary from student to student):
FTEC2101/ESTR2520 Project 8
1.2 Competitive Tasks (30%)
The goal of this competitive task is to implement your solver to the binary classifier problem, without relying
on JuMP and its optimizers such as ECOS, Juniper, etc. as we have done so in the previous tasks. To motivate, we observe that while optimization packages such as JuMP are convenient to use, they are often limited
by scalability to large-scale problems when the number of training samples m ≫ 1 and/or the feature is high
dimensional d ≫ 1. The task would require considerably more advanced coding skills.
We shall consider the full dataset and utilize all the 64 available attributes to detect bankruptcy. Our
objectives are to find a classifier with the best training/testing error and the sparsest feature selection.
Our requirement is that (i) the classifier has to be found using a custom-made iterative algorithm such as
projected gradient descent for solving an optimization problem of the form:
min
w∈Rd,b∈R
fb(w, b) s.t. (w, b) ∈ X, (1.4)
where (ii) fb(·) shall be built using the provided training dataset and X ⊆ R
d × R is a convex set.
You are recommended to consider the logistic loss3 as we have done in Lecture 16 / Computing Lab 2:
Minimizing the above function leads to a solution (w, b) such that y
which makes a desired feature for a good classifier. Moreover, as inspired by Task 4, we may take
Our task is specified as follows.
Task 6: Customized Solver for Classifier Optimization (30%)
Using the dataset with the training data from m = 8000 samples in ftec-full-train.csv. Implement
an iterative algorithm to tackle (1.4). You are required to initialize your algorithm by w0 = 0, b0 = 0.
Suggestion: As the first attempt, you may consider the projected gradient descent (PGD) method using
a constant step size with fb(w, b) selected as the logistic function (1.5) and using the projection onto the
set X in (1.6). See Appendix A for the solution of the projection operator onto this X.
Assessment You will receive a maximum of 10% for correctly implementing at least one numerical algorithm (e.g., projected gradient), together with
1. plotting the trajectory of the algorithm is show that the objective value in (1.4) to be decreasing to a
certain value asymptotically and providing comments on the algorithm(s) implemented,
2. providing derivations and justifications on why the implemented algorithm is used.
3Notice that the logistic objective function can be interpreted alternatively as a formulation for the classifier design task with
the maximum-likelihood (ML) principle from statistics. This is beyond the scope of this project specification.
FTEC2101/ESTR2520 Project 9
We will also use the F1 score which is a common metric to evaluate the classifier performance:
F1 =
2(1 − PMD)
2(1 − PMD) + PF A + PMD
,
See https://en.wikipedia.org/wiki/F-score. Moreover, the number of non-zero elements in (w, b) will be
calculated according to the normalized version of latter, and
(# non-zero elements in w, b) = 1
i.e., the magnitude has to be large enough relative to the other elements. For convenience, we have provided
the functions f1 score, no of nonzeros for you in the project template which can be directly used. The
remaining 20% of your marks in this task will be calculated according to the following formula:
Score = 7.5% × exp
10 · min{0.75, Your Training F1} − 10 · min{0.75, Highest Training F1}
+ 7.5% × exp
10 · min{0.75, Your Testing F1} − 10 · min{0.75, Highest Testing F1}
+ 5% ×
max{4, Lowest number of non-zero elements in w, b}
max{4, Your number of non-zero elements in w, b}
. (1.7)
The highest F1 are the highest one among the class of FTEC21014
. Some tips for improving the performance
of your design can be found in Appendix B.
If you have tried more than one algorithm and/or more than one type of approximation, algorithm parameters,
you have to select only one set of classifier parameters (w, b) for consideration of the competition in (1.7).
Please indicate clearly which solution is selected in your report and include that in the submission of your
program files. That said, you are encouraged to try more of these different variants and include them in the
project report. Moreover, observe the following rules:
• The algorithms you designed are not allowed to directly optimize on the testing set data. In other
words, your iterative algorithm should not rely on any data in ftec-full-test.csv as you are not
supposed to see the ‘future company’ data while training a classifier. Your score in (1.7) will be set to
zero if we detect such ‘cheating’ behavior. However, you can evaluate the test error performance of your
solution as many time as you like before you find the best setting.
• Your selected algorithm for the competition must be deterministic and terminates in less than 104
iterations. In other words, you can not use stochastic algorithms such as stochastic gradient descent
(SGD) for the competition. That being said, you are encouraged to try such algorithms as an additional
task which may be counted towards the ‘innovation’ section.
If you have questions about the rules, please do not hesitate to consult the instructor at htwai@cuhk.edu.hk
or the TA or ask on Piazza.
1.3 Report (20%)
You are required to compile a project report with answers to the questions posed in Task 1 to Task 6. For
your reference only, you may structure the report according to the order of the tasks:
4The scores for ESTR2520 students will be calculated by taking the best error performance across both ESTR2520 and
FTEC2101 students.
FTEC2101/ESTR2520 Project 10
1. Background and Introduction — In this section, you can briefly introduce the problem, e.g., explaining the goal of classifier design, discussing the role of optimization methods in tackling the problem.
2. Model and Theory — In this section, you can discuss how the classifier design problem is modeled as
optimization problems. More specifically,
– You may begin by discussing the soft-margin formulation (1.2) and then answer Task 1.
– Next, you can describe the optimization models and then answer Task 2.
3. Experiments — In this section, you describe the experiments conducted to test your formulation, i.e.,
– You may first describe the dataset by presenting the results from Task 3. In addition, it is helpful to
describe a few properties regarding the dataset, e.g., the size of the dataset, the range of the values for
the different features.
– Then, you can describe the experiments for each of the 3 formulations with the results from Task 4.
– Finally, you can compare the formulations by answering Task 5.
4. Competitive Task — In this section, you describe the custom solver you built to solve the large-scale
classifier design problem, i.e.,
– You shall first describe your formulation as laid out in the discussion of Section 1.2.
– Then, you shall describe the iterative algorithm you have derived in Task 6.
– Apply the iterative algorithm on the complete training dataset and show the objective value vs. iteration number. Discuss whether the algorithm converges and report on the performance of the designed
classifier.
5. Conclusions — In this section, you shall summarize the findings in the project, and discuss various
aspects that can be improved with the formulation, etc..
Throughout the report, please feel free to write your answer which involves equations (e.g., Task 1-2) on a paper
and scan it to your Word/PDF report as a figure. On the other hand, if you wish to typeset the mathematics
formulas in your report nicely, you are strongly recommended to use Latex, e.g., http://www.overleaf.com
(P.S. This project specification, and other lecture materials in this course have all been typesetted in Latex).
For the latter, a Latex template has been provided on Blackboard.
For Task 3 to 6, please include all the plots and comments as requested. For Task 6, please indicate the
Training F1, Testing F1, No. of non-zero elements in w for your selected solution. We will also run your
code to verify the values reported and take the ones obtained from your code.
The program code in .ipynb has to be submitted separately. However, you are welcomed to use excerpts from
the program codes in the report if you find it helpful for explaining your solution concepts.
Lastly, you are welcomed to use online resources when preparing the project. However, you must give proper
references for sources that are not your original creation.
Assessment Here is a breakdown of the assessment metric for the report writing component.
• (10%) Report Writing: A project report shall be readable to a person with knowledge in optimization
(e.g., your classmates in FTEC2101/ESTR2520). Make sure that your report is written with clarity, and
more importantly, using your own language!
FTEC2101/ESTR2520 Project 11
• (10%) Innovation: You can get innovation marks if you include extra experiments, presentations,
etc.. that are relevant to the project (with sufficient explanations); see Appendix A for some recommendations.
1.4 Submission
This is an individual project. While discussions regarding how to solve the problems is encouraged, students
should answer the problems on their own (just like your HWs). The deadline of submission is May 10 (Friday),
2024, 23:59 (HKT). Please submit with the following content to Blackboard:
• Your Project Report in PDF format.
• Your Program Codes [either in Jupyter notebook (.ipynb), or Julia code (.jl)].
In addition, the project report shall be submitted to VeriGuide for plagiarism check.
A Dataset Description
Here is the list of all the 64 features collected in the Bankruptcy dataset:
Attr1 net profit / total assets
Attr2 total liabilities / total assets
Attr3 working capital / total assets
Attr4 current assets / short-term liabilities
Attr5 [(cash + short-term securities + receivables - short-term liabilities)
/ (operating expenses - depreciation)] * 365
Attr6 retained earnings / total assets
Attr7 EBIT / total assets
Attr8 book value of equity / total liabilities
Attr9 sales / total assets
Attr10 equity / total assets
Attr11 (gross profit + extraordinary items + financial expenses) / total assets
Attr12 gross profit / short-term liabilities
Attr13 (gross profit + depreciation) / sales
Attr14 (gross profit + interest) / total assets
Attr15 (total liabilities * 365) / (gross profit + depreciation)
Attr16 (gross profit + depreciation) / total liabilities
Attr17 total assets / total liabilities
Attr18 gross profit / total assets
Attr19 gross profit / sales
Attr20 (inventory * 365) / sales
Attr21 sales (n) / sales (n-1)
Attr22 profit on operating activities / total assets
Attr23 net profit / sales
Attr24 gross profit (in 3 years) / total assets
Attr25 (equity - share capital) / total assets
Attr26 (net profit + depreciation) / total liabilities
Attr27 profit on operating activities / financial expenses
Attr28 working capital / fixed assets
Attr29 logarithm of total assets
FTEC2101/ESTR2520 Project 12
Attr30 (total liabilities - cash) / sales
Attr31 (gross profit + interest) / sales
Attr32 (current liabilities * 365) / cost of products sold
Attr33 operating expenses / short-term liabilities
Attr34 operating expenses / total liabilities
Attr35 profit on sales / total assets
Attr36 total sales / total assets
Attr37 (current assets - inventories) / long-term liabilities
Attr38 constant capital / total assets
Attr39 profit on sales / sales
Attr40 (current assets - inventory - receivables) / short-term liabilities
Attr41 total liabilities / ((profit on operating activities + depreciation) * (12/365))
Attr42 profit on operating activities / sales
Attr43 rotation receivables + inventory turnover in days
Attr44 (receivables * 365) / sales
Attr45 net profit / inventory
Attr46 (current assets - inventory) / short-term liabilities
Attr47 (inventory * 365) / cost of products sold
Attr48 EBITDA (profit on operating activities - depreciation) / total assets
Attr49 EBITDA (profit on operating activities - depreciation) / sales
Attr50 current assets / total liabilities
Attr51 short-term liabilities / total assets
Attr52 (short-term liabilities * 365) / cost of products sold)
Attr53 equity / fixed assets
Attr54 constant capital / fixed assets
Attr55 working capital
Attr56 (sales - cost of products sold) / sales
Attr57 (current assets - inventory - short-term liabilities) / (sales - gross profit - depreciation)
Attr58 total costs /total sales
Attr59 long-term liabilities / equity
Attr60 sales / inventory
Attr61 sales / receivables
Attr62 (short-term liabilities *365) / sales
Attr63 sales / short-term liabilities
Attr64 sales / fixed assets
B Additional Information
Suggestions — The below are only suggestions for improving the performance of your classifier design in
Task 6. You are more than welcomed to propose and explore new ideas (but still, make sure that they are
mathematically correct – feel free to ask the instructor/TA if in doubt)!
• Formulation Aspect – Here are some tricks to tweak the performance of your classifier design in Task 6.
1. The design of the weights {ℓi}
m
i=1 maybe crucial to the performance of your classifier. Like what you did
in Task 5, try tuning the parameter weight to get better performance.
2. The value of R1 in (1.6) is crucial to the sparsity of the classifier found.
3. The logistic regression loss (1.5) is not the only option. Some reasonable/popular options can be found
in https://www.cs.cornell.edu/courses/cs4780/2022sp/notes/LectureNotes14.html.
• Algorithm Aspect – For Task 6, the recommended algorithm is projected gradient descent (PGD) method,
FTEC2101/ESTR2520 Project 13
which are described as follows. For solving a general optimization:
min
w∈Rd,b∈R
fb(w, b) s.t. (w, b) ∈ X. (1.8)
With a slight abuse of notation, we denote x ≡ (w, b) and the PGD method can be described as
PGD Method
Input: x
(0) ∈ X, constant step size γ > 0, max. iteration number Kmax.
For k = 0, ..., Kmax
x
(k+1) = ProjX
x
(k) − γ∇fb(x
(k)
)
End For
The book [Beck, 2017] is a good reference for learning different optimization algorithms.
When X = {x ∈ R
d
:
Pd
i=1 |xi
| ≤ R} as in (1.6), the projection operator is (see [Duchi et al., 2008])
1. Input: x ∈ R
d
, R > 0.
2. Calculate the vector u = abs.(x) such that it takes the absolute values of the input x.
3. Sort elements in u with decreasing magnitude, denote the sorted vector as v, |v1| ≥ · · · ≥ |vd|.
4. For j = 1, ..., d,
If vj −
1
j
Pj
r=1 vr − R
≤ 0, Then set jsv = j − 1 and break the for-loop.
5. Set θ =
1
jsv Pjsv
r=1 vr − R
.
6. Return: the vector xˆ such that ˆxi = sign(xi) max{0, |xi
| − θ} for i = 1, ..., d.
Besides, you are more than welcomed to explore the use of other iterative algorithms, e.g., conditional
gradient, back tracking line search, etc., for solving the optimization at hand.
Lastly, tips for implementing the MI-NLP, SOCP, etc.. in the compulsory tasks have been included with the
the template program. Be reminded that it is not necessary to follow all the tips therein.
C On the Use of Generative AI Tools
We are following Approach 3 as listed in the University’s Guideline on the matter: https://www.aqs.
cuhk.edu.hk/documents/A-guide-for-students_use-of-AI-tools.pdf — Use of AI tools is allowed with
explicit acknowledgement and proper citation. In short, you are allowed to use generative AI tools to assist
you, provided that you give explicit acknowledgement to the use of such tools, e.g., you may include a
sentence like:
The following section has been completed with the aid of ChatGPT.
Failure to do so will constitute act of academic dishonesty and may result in failure of the course and/or other
penalties; see https://www.cuhk.edu.hk/policy/academichonesty/. Below we list a number of advices for
the do’s and don’ts using AI tools:
• DO’s: You may use AI tools for polishing your writeups, e.g., to correct grammatical mistakes, typos,
or summarizing long/complicated paragraphs, etc. The results are usually quite robust especially for
improving the writings from less experienced writers. Of course, you are responsible for the integrity of
the edited writing, e.g., check if the AI tools have distorted the meaning of your original writeups or not.
FTEC2101/ESTR2520 Project 14
• DON’Ts: You should not ask AI tools to solve mathematical questions. Not only this will spoil the
purpose of learning, AI tools do a notoriously bad job for tasks involving facts and mathematical/logical
reasoning. Worst still, they tend to produce solutions that sound legit but are completely wrong.
• DON’Ts: You should not ask AI tools to write the entire project (report) for you. Likewise, AI tools
are notoriously bad at creating (technical and logical) content. They tend to produce writings that sound
legit but are completely illogical.
We believe that when properly used, they can be helpful in improving students’ overall learning experience.
In fact, you are even encouraged to try them out at your leisure time. Nevertheless, we emphasize again that
you have to provide explicit acknowledgement in your submission if you have used any generative AI tools
to assist you in this course.
References
A. Beck. First-order methods in optimization. SIAM, 2017.
J. Duchi, S. Shalev-Shwartz, Y. Singer, and T. Chandra. Efficient projections onto the l 1-ball for learning in
high dimensions. In Proceedings of the 25th international conference on Machine learning, pages 272–279,
2008.
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- instagram最好用的群发软件推荐,ins营销推广引流工具
- 代写OpenCV to produce a stabilised video
- 2024上海环境监测展预登记开启,带您领略行业尖端技术与产品
- 数字的盛宴 WhatsApp拉群营销工具 我的营业额节节攀升 客户询盘数暴增500%
- 数字大法宝 科技魔法师揭秘 在WhatsApp拉群营销工具的世界里开启业务新篇章
- 华胜天成荣登“2024新质生产力标杆企业百强”榜单
- 代写Stochastic Processes、代做Python设计编程
- WhatsApp群发拉群业务,ws协议号出售/ws印度号咨询大轩
- 群发大数据时代,挑战创意极限:LINE营销工具助你创造推广的独特风格Line群发云控让您的推广更具针对性
- 仅售9999的轮足机器人 看松灵如何重新定义开发性和可玩性双性能
- 外贸新星的成长之路 WhatsApp拉群工具为我解锁了业务的新奇门道
- 智能肿瘤学知识库启动 神州医疗以AI创新驱动医疗变革
- 窥见未来,Anyty[艾尼提]工业内窥镜在科研院所应用的巨大潜能
- ins群发营销软件,instagram营销软件,天宇爆粉【TG:@cjhshk199937】
- 山西木业行业网:传承与创新,共筑绿色木业未来
- 世和基因与南京鼓楼医院签约研产融合共建
- VSP2101YG4: Revolutionizing Video Signal Processing for Enhanced Visual Experiences | ChipsX
- Instagram营销软件,ins定位采集工具/采集全球任意国家
- Ins群发营销工具,Instagram打粉工具,助你成为行业翘楚!
- 家居建材网:打造您的理想家居,一站式购物新体验
- instagram营销软件,ins协议群发,联系天宇群发预约测试
- Ins批量筛选群发营销采集神器,Instagram助你打造营销新局面!
- WhatsApp群发拉群业务,ws协议号出售/ws印度号咨询大轩
- 走向国际市场新高度,Telegram协议号注册器为您保驾护航
- Ig引流教程,Instagram批量养号,ins自动群发工具
- ins拉群软件:智能品牌推广的引擎
- 极空间私有云勇夺第一季度京东NAS网络存储行业双冠军
- 心花怒放 WhatsApp拉群营销工具为我的生意注入了蓬勃的活力
- 贵州桃花源新型材料有限公司负氧离子黄晶板整装动静相宜,让人眼前一亮
- Ins高效群发软件,Instagram智能监控引流软件带你成为外贸专家!
推荐
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
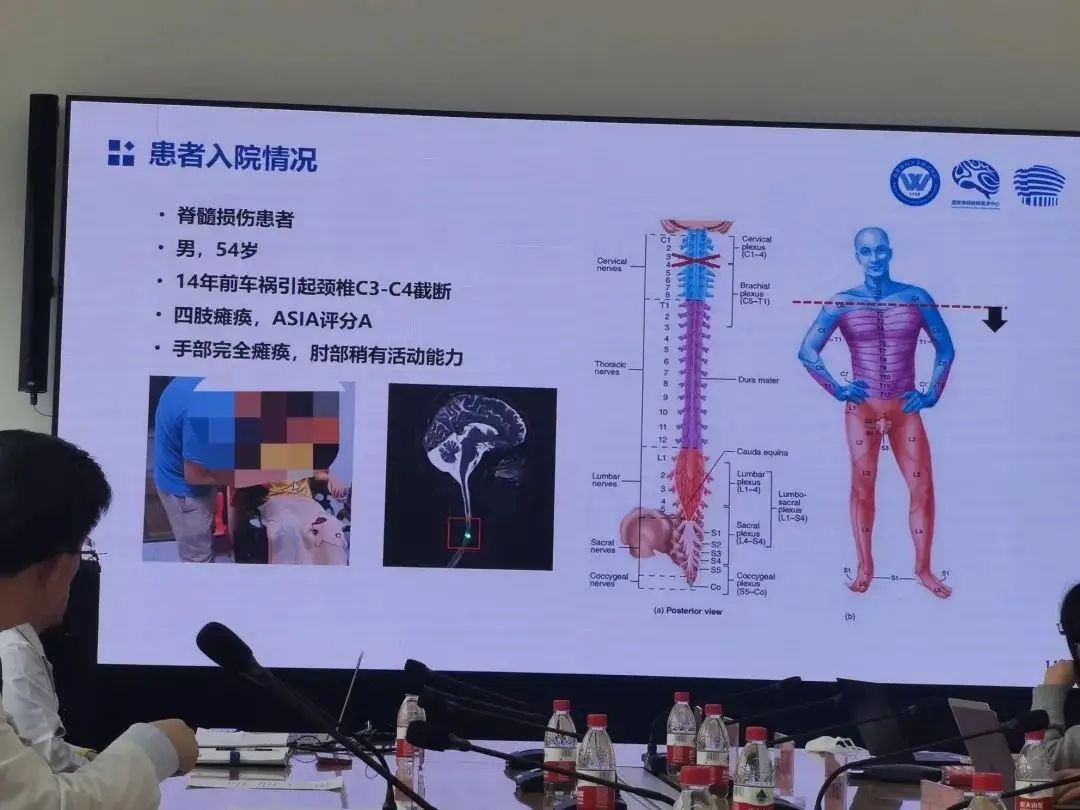 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技