
代写Deep Learning、代做Python设计程序
Deep Learning / Spring 2024
Homework 3
Please upload your assignments on or before May 6, 2024.
• You are encouraged to discuss ideas with each other. But you must acknowledge your collaborator, and you must compose your own writeup and code
independently.
• We require answers to theory questions to be written in LaTeX. (Figures can be
hand-drawn, but any text or equations must be typeset.) Handwritten homework
submissions will not be graded.
• We require answers to coding questions in the form of a Jupyter notebook. It is
important to include brief, coherent explanations of both your code and your
results to show us your understanding. Use the text block feature of Jupyter
notebooks to include explanations.
• Upload both your theory and coding answers in the form of a single PDF on
Gradescope.
1. (5 points) Understanding policy gradients. In class we derived a general form
of policy gradients. Let us consider a special case here which does not involve
any neural networks. Suppose the step size is η. We consider the so-called bandit
setting where past actions and states do not matter, and different actions ai give
rise to different rewards Ri
.
a. Define the mapping π such that π(ai) = softmax(θi) for i = 1, . . . , k,
where k is the total number of actions and θi
is a scalar parameter encoding
the value of each action. Show that if action ai
is sampled, then the change
in the parameters is given by:
∆θi = ηRi(1 − π(ai)).
b. If constant step sizes are used, intuitively explain why the above update
rule might lead to unstable training. How would you fix this issue to ensure
convergence of the parameters?
2. (5 points) Minimax optimization. In this problem we will see how training GANs
is somewhat fundamentally different from regular training. Consider a simple
problem where we are trying to minimax a function of two scalars:
You can try graphing this function in Python if you like (no need to include it in
your answer.
1
a. Determine the saddle point of this function. A saddle point is a point
(x, y) for which f attains a local minimum along one direction and a local
maximum in an orthogonal direction.
b. Write down the gradient descent/ascent equations for solving this problem
starting at some arbitrary initialization (x0, y0).
c. Determine the range of allowable step sizes to ensure that gradient descent/ascent converges.
d. (2 points). What if you just did regular gradient descent over both variables
instead? Comment on the dynamics of the updates and whether there are
special cases where one might converge to the saddle point anyway.
3. (5 points) Generative models. In this problem, the goal is to train and visualize
the outputs of a simple Deep Convolutional GAN (DCGAN) to generate realisticlooking (but synthetic) images of clothing items.
a. Use the FashionMNIST training dataset (which we used in previous assignments) to train the DCGAN. Images are grayscale and size 28 × 28.
b. Use the following discriminator architecture (kernel size = 5 × 5 with stride
= 2 in both directions):
• 2D convolutions (1 × 28 × 28 → 64 × 14 × 14 → 128 × 7 × 7)
• each convolutional layer is equipped with a Leaky ReLU with slope
0.3, followed by Dropout with parameter 0.3.
• a dense layer that takes the flattened output of the last convolution and
maps it to a scalar.
Here is a link that discusses how to appropriately choose padding and stride values
in order to desired sizes.
c. Use the following generator architecture (which is essentially the reverse of
a standard discriminative architecture). You can use the same kernel size.
Construct:
• a dense layer that takes a unit Gaussian noise vector of length 100 and
maps it to a vector of size 7 ∗ 7 ∗ 256. No bias terms.
• several transpose 2D convolutions (256 × 7 × 7 → 128 × 7 × 7 →
64 × 14 × 14 → 1 × 28 × 28). No bias terms.
• each convolutional layer (except the last one) is equipped with Batch
Normalization (batch norm), followed by Leaky ReLU with slope 0.3.
The last (output) layer is equipped with tanh activation (no batch norm).
d. Use the binary cross-entropy loss for training both the generator and the
discriminator. Use the Adam optimizer with learning rate 10−4
.
e. Train it for 50 epochs. You can use minibatch sizes of 16, 32, or 64. Training
may take several minutes (or even up to an hour), so be patient! Display
intermediate images generated after T = 10, T = 30, and T = 50 epochs.
2
If the random seeds are fixed throughout then you should get results of the
following quality:
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- Yeelight易来宣布通过Works with Sonos认证,打造顶级智能声光体验
- Line协议号注册器市场巅峰:我的LINE营销工具心得,让你事业一飞冲天
- Instagram批量养号 - ins定位采集/ig私信博主/ins批量养号
- TG全面群发营销平台,电报精准群发软件,Telegram自动化营销工具
- 外贸新星 从零开始 WhatsApp拉群工具助我腾飞成为外贸小霸王
- Telegram营销软件如何主宰群发筛选引流市场
- ADF4360-3BCP: Enabling Precision Frequency Synthesis in Wireless Communication Systems | ChipsX
- Telegram营销软件群发引流神器,TG营销引流一键搞定
- Telegram群发营销软件,快速开拓TG引流市场
- 数字经济时代,环保水务科技产业十大战略技术趋势
- 新品新技术+豪华品牌+高端会议!2024广东水展整装待发,你想要的这儿都有!
- 用WhatsApp拉群工具进行推广 每一次成功的转化都带来一波生意的喜悦浪潮
- 【潮玩外设,闪耀魔都】佳达隆携多款新品亮相上海装备前线键盘节!
- Instagram营销群发利器,ins引流攻略,ig营销出海教程
- Ins引流营销助手,Instagram拉群群发软件,助你快速壮大粉丝团!
- 打造全球业务网络,CE Channel为您寻找最佳国际合作伙伴!
- 数字奇兵:科技魔法师驾驭WhatsApp拉群,点燃市场风暴
- Optimisation代做、代写Optimisation编程设计
- SEHH2042代做、c/c++程序设计代写
- 会议室显示屏怎么选?皓丽会议平板还是会议电视
推荐
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
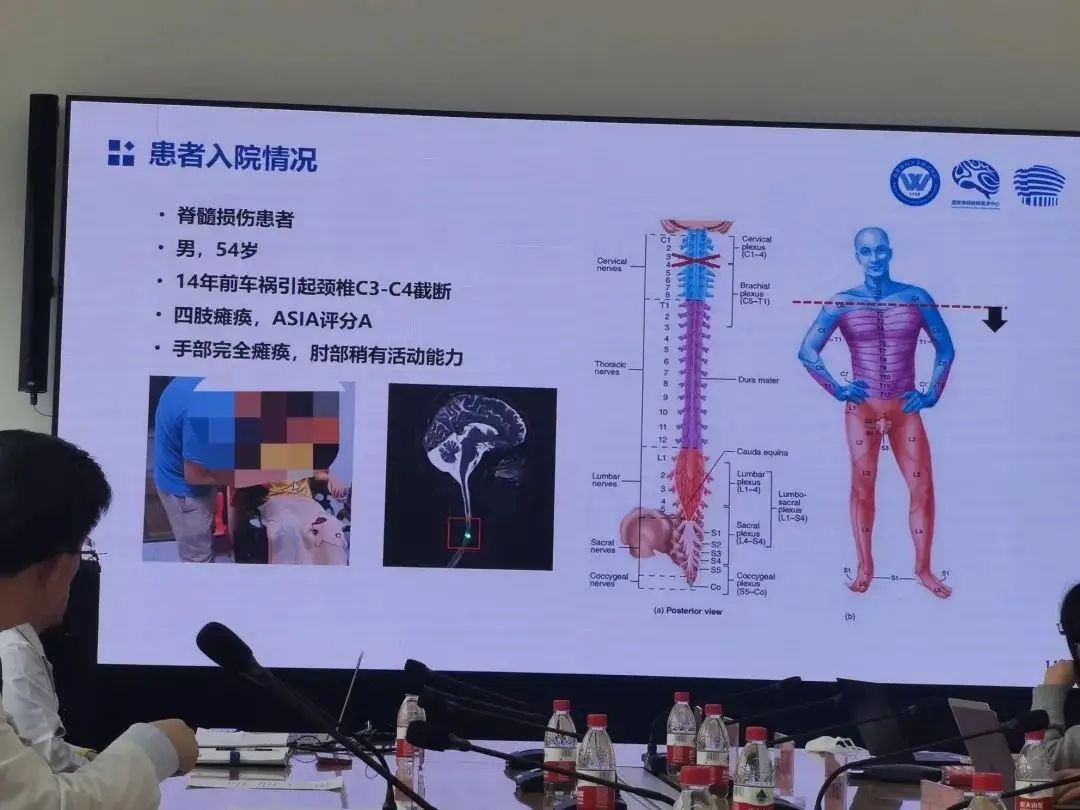 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
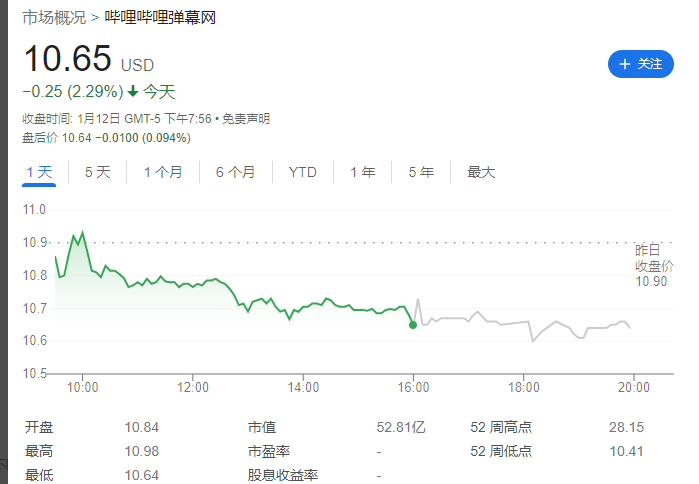 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技