
代写CSC 330、代做C/C++编程语言
CSC 330 Programming Languages
Project
Note 1 This project is to be done individually
Note 2 Working with other people is prohibited.
Note 2 Sharing queries or files with other people is prohibited.
A note on Academic Integrity and Plagiarism
Please review the following documents:
• Standards for Professional Behaviour, Faculty of Engineering:
https://www.uvic.ca/engineering/assets/docs/professional-behaviour.pdf
• Policies Academic Integrity, UVic:
https://www.uvic.ca/students/academics/academic-integrity/
• Uvic’s Calendar section on Plagirism:
https://www.uvic.ca/calendar/undergrad/index.php#/policy/Sk_0xsM_V
Note specifically:
Plagiarism
Single or multiple instances of inadequate attribution of sources should result in a failing grade
for the work. A largely or fully plagiarized piece of work should result in a grade of F for the
course.
Submissions will be screened for plagiarism at the end of the term.
You are responsible for your own submission, but you could also be responsible if somebody plagiarizes
your submission.
1 Objectives
After completing this project, you will have experience:
• Programming Functionally
• Basket analysis in big datasets using the A-priori algorithm
2 The A-priori algorithm
The A-priori algorithm is used to identify commonly found groups of items in basket analysis. For example,
if you buy milk, what other item are you likely to buy?
The input file to this algorithm will be a CSV file. Each CSV file is a set of transactions, one per line. A
transaction is a set of items sold together (each item is separated by a delimiter character). A transaction is
guaranteed to have no duplicate items.
1
Our goal is to identify pairs of items that are sold together above certain minimum threshold. A minimum
support threshold is the minimum proportion of transactions an item should appear in order to be be part of
the output (we will call these popular items).
The A-priori algorithm is relatively simple. Assume that i is the number of different items in the dataset,
and n is the number of popular items. Using dictionaries as the main data structure, the memory requirements
for this algorithm are O(max(n
2
, i)) irrespectively of the size of the input (which can be much larger than
the available memory). To accomplish this, the algorithm does two passes on the input data.
• First pass. In the first pass of all transactions, a dictionary of popular items is computed. This dictionary will have as its key the item name, and as its value its frequency (number of transactions where
the item appears). After all transactions are read, compute the minimum support (an integer computed
by multiplying the minimum support threshold by the number of transactions, truncating this number,
i.e. floor). Return a dictionary that contains only the popular items. The result of the first pass is a
dictionary that contains only popular items.
• Second pass. Read the transactions again. This time keep a counter of popular pairs of items. The key
will be the pair of items (item1, item2). The frequency is symmetric, freq(item1, item2) = freq(item2,
item1). For this reason the dictionary should keep only one copy per pair (e.g. order them such
that given item1, item2, the key to the dictionary is always (min(item1,item2), max(item1,item2)).
Return a dictionary that contains only the popular pairs of items. The result of the second pass is a
dictionary that contains only popular pairs of items.
• Report the results. Using the two dictionaries, print a table with the results. See below for details.
Note that some CSV files use ’,’ and some ’;’ as a separator.
3 Your task, should you choose to accept it
Implement 3 functions that implement the 3 steps of the A-priori algorithm
3.1 Preliminaries: how to run your program
Your program is run with the following arguments. See the Makefile for the specifics of how to compile and
run the program. You will find in the Makefile 4 test cases.
<filename> <delimiter> <MinimumSuportThreshold> <linesToPrint>
• filename. A CSV delimited file. One record per line. You can assume there are no duplicates in a
record.
• delimiter. A one character string that indicates the separator between items in a record. Use quotes
around it to avoid the shell to interpret the character.
• MinimumSuportThreshold. The minimum support threshold that an pair should have to be part of the
output (between 0 and 1)
• linesToPrint. Print at most this number of items. If the result has more frequent items than this
number, print only this number of pairs.
2
For example, the command:
./apriori online.csv ’,’ .01 10
uses the file online.csv with delimiter , (comma) and minimum support threshold of 0.01 and requests to print at most the first 10 items.
3.2 Implementation details
Download from Gitlab the tar file. It contains several files. You will only modify and submit apriori.ml.
Note that this file defines a module that must match the signature provided.
Your job is to implement 3 functions:
3.3 First Pass
let do_first_pass ((threshold: float),
(lines: in_channel),
(delim: char)): first_pass_result =
This function takes three parameters:
1. threshold: The minimum threshold (between 0 and 1),
2. lines: a input stream from where to read the lines,
3. delim: the delimiter of the items in each line (a char).
Read the stream with the function input line. Note that this function generates an exception (that
you must handle) when the end of file is reached.
do first pass should return a record with 3 values (see apriori.ml for the definition of the record):
1. the number of transactions in the stream,
2. the minimum support (i.e. the minimum number of times a frequent item should appears), and
3. the dictionary of the frequent items with their corresponding frequency.
To compute the minimum support truncate the floating point number to an integer. The dictionary should
contain only items with at least this support.
3.3.1 Second Pass
let do_second_pass((support: int),
(popItems: items_dict),
(lines: in_channel),
(delim:char)): pairs_dict =
This function takes 4 parameters:
3
1. support: the minimum support (an integer),
2. popItems: the dictionary of frequent items,
3. lines: the input stream with the transactions,
4. delim: the delimiter (a char)
It should return a dictionary that contains the popular pairs equal or above the minimum support threshold and their corresponding frequency.
3.4 print table
let print_table((nTransactions: int),
(popItems: items_dict),
(popPairs: pairs_dict),
(toPrint:int)):int =
This function prints a table with the popular pairs, and some extra information. It takes 4 parameters:
1. nTransactions is the number of records in the file (result of first pass).
2. popItems is the popular items (result of the first pass),
3. freqPairs is the list of popular pairs (result of the second pass).
4. toPrint: print at most a given number of pairs.
The columns of these report are:
• Support of the pair: the proportion of transactions that have this pair.
• The item name.
• The frequency of this item. Number of transactions where this item appears.
• The support of this item. The proportion of transactions that include this item.
• The other item in the pair.
• The frequency of this pair. Number of transactions where this pair appears.
• Confidence: the support of the pair divided by the support of other item. This number represents the
proportion of transactions of the second item where the first item appears. When it one it means that
every time the second item appears, the first also appears.
• Lift. The support of the pair divided by the product of the support of both items.
Running with parameters: Filename [./data/online.csv] Separator [,] Minimum relative support threshold
[0.01] and Print at most 10 tuples.
4
SuppPair-Item - Freq- Support-With - FreqPair- Conf. - Lift
0.010887 regency tea plate green 386 0.014902 regency tea plate pink 282 0.898 60.265
0.010501 regency tea plate roses 457 0.017643 regency tea plate pink 272 0.866 49.097
0.012431 regency tea plate roses 457 0.017643 regency tea plate green 322 0.834 47.281
0.010887 wooden star christmas scandinavian 515 0.019883 wooden tree christmas scandinavian 282 0.832 41.838
0.013512 set/6 red spotty paper plates 527 0.020346 set/6 red spotty paper cups 350 0.818 40.193
0.024863 green regency teacup and saucer 1057 0.040808 pink regency teacup and saucer 644 0.804 19.702
0.010154 poppy’s playhouse kitchen 440 0.016987 poppy’s playhouse livingroom 263 0.797 46.916
0.010115 poppy’s playhouse bedroom 426 0.016447 poppy’s playhouse livingroom 262 0.794 48.274
0.013512 small dolly mix design orange bowl 528 0.020385 small marshmallows pink bowl 350 0.781 38.326
0.012354 bathroom metal sign 709 0.027372 toilet metal sign 320 0.780 28.514
Number items printed: 10
Number transactions: 25902
Number popular items: 592
Number popular pairs: 746
The results should be ordered according to (think order by in SQL):
1. confidence descending,
2. lift descending,
3. item frequency descending,
4. item name, ascending,
5. item name it appears with, ascending.
Use these bindings to format the output (they are defined in apriori.ml):
let lineTitleFormatString = format_of_string
" SuppPair-%s - Freq- Support-%s - FreqPair- Conf. - Lift
"
let lineDataFormatString = format_of_string
"%9.6f %s %6d %8.6f %s %6d %9.3f %9.3f
"
These work in the same way than printf in C. Use Note that the columns for both items (%s) do not
have a width specification. This is because their width will be dynamically computed. The width of each of
the columns is the maximum width of any of the corresponding items to be printed (but cannot be less than
10 characters).
3.5 Tests
The files you downloaded contain several tests. The directory expected contains the expected output. The
directory data contains four datasets. See the Makefile to understand how to run the program and generate
each output. Use diff to compare your output to the expected one (see Makefile).
Your program’s output should be identical to the expected output for the same command line and input
dataset.
3.6 Dictionaries
The dictionaries used in this assignment are non-mutable. As with our assignments, when we insert or delete
from a dictionary, a new dictionary is created. Unfortunately it means that to update a value, you have to
remove it and insert it again. The dictionaries are defined in the file dicts.ml.
To create a dictionary of type ItemMap use Dicts.ItemMap.empty.
To find a value in a dictionary use Dicts.ItemMap.add key value dictionary.
To remove a value use Dicts.ItemMap.remove key dictionary. Both functions are curried.
5
3.7 Grading
The grading is divided into 3 parts:
• First pass: 30%
• Second pass: 30%
• Report: 40%
Your functions will be tested one at a time, using the signature provided.
Your program will be tested in Linux.csc.uvic.ca. Make sure it compiles there. If your program does not
compile, it will receive a zero.
If your program generates any warnings, it will receive a zero.
3.8 Hints
1. The algorithm is relatively straightforward, most of the code you will write is to parse the input and
to format the output.
2. Do not read the stream more than once per pass, because you function might run out of memory.
This means you need to compute its length as you are processing it.
3. Be careful with the output. Your program’s output should match byte-by-byte the expected output.
4. For anything not precisely specified here, see expected output and check/ask in brightspace. There
will a forum to discuss the assignment.
3.9 Other information and restrictions
Violating any of the following restrictions will result in a grade of zero:
1. No mutation.
2. The input stream should not be processed more than once in each function.
3. Your functions should read only one line at a time. You cannot read the entire input stream to
memory.
You can share test cases with others but you are forbidden from sharing source code.
4 What to submit
Submit, via Brigthspace:
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- 一根针穿起基层治理千条线,万科物业首次公开管家服务标准
- WhatsApp拉群的步骤是什么
- instagram群发引流必备,高效采集用户,助你实现社交爆粉!
- Ins/Instagram营销采集机器人,ins博主粉丝精准采集利器全新登场!
- 从小白到高手 她在海外市场使用WhatsApp拉群工具 社交媒体影响力上涨了70%
- 文心大模型日调用量超5000万次
- 新华三助力中国邮政私有云平台建设
- CE-Channel: Streamline Your International Business Expansion with Instant Global Partner Connections
- Instagram引粉营销神器,ins全球引流营销必选软件大公开!
- 突破创意瓶颈 WhatsApp拉群营销工具助你走向创意的新高度
- 中国企业家木兰汇参访星期零,共话健康饮食和女性力量
- 开学第一课:做好近视管理,别让孩子视力“掉队”!
- 北京爱尔英智眼科医院范春雷为母子俩施眼外斜手术,眼病、心病都好了!
- “人工心脏”仅核桃大小,植入男子心尖后重获新生
- 时空黑匣子,深藏着无尽的秘密与谜团。WhatsApp拉群营销工具
- Instagram营销群发软件,Ins一键群发工具,助你实现营销梦想!
- 2024广东水展即将开幕 | 聚焦净水行业热点 抢占行业新机遇!
- 外贸菜鸟成长记 WhatsApp拉群营销工具让我轻松打开国际市场大门
- Instagram,ins最强涨粉工具,打造ins引流推广新天地!
- 电报一键群发,快速引流!Telegram营销利器助你轻松拉群
- 走向国际市场新高度,Telegram协议号注册器为您保驾护航
- instagram怎么自动采集博主粉丝?ins精准批量采集软件推荐
- TG-WS-LINE频道号,直登号,协议号,老号,怎么识别可靠的代筛全球app机构
- 趋势跟手WhatsApp工具助我快速融入外贸市场不再错失良机
- 易智瑞:自然资源数字化治理能力提升关键技术解读
- Instagram引流爆粉营销工具,Ins群发工具,带你实现营销逆袭!
- Ins群发脚本营销软件,Instagram一键群发工具,让你打造营销新格局!
- 业务革新:WhatsApp拉群营销工具是我事业崛起的关键驱动
- 高效筛选TG-WS-LINE云控/自动注册机/筛料/群发炸粉:如何利用Line代筛料子提高数据处理效率
- 今天 我要向大家介绍的 就是这样一款神奇的营销利器 WhatsApp拉群营销工具
推荐
-
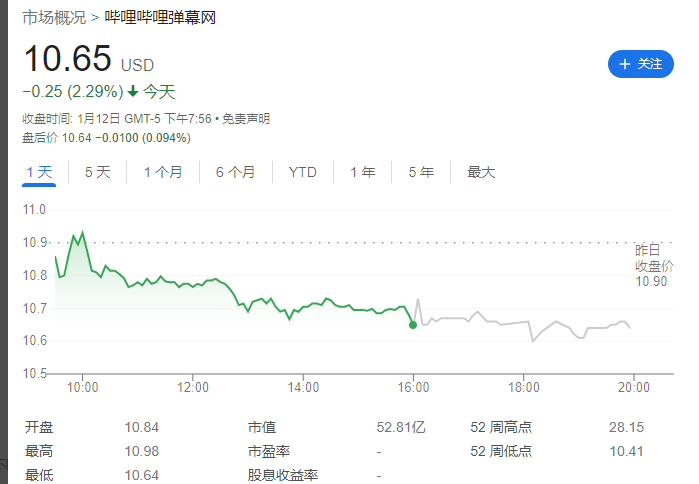 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
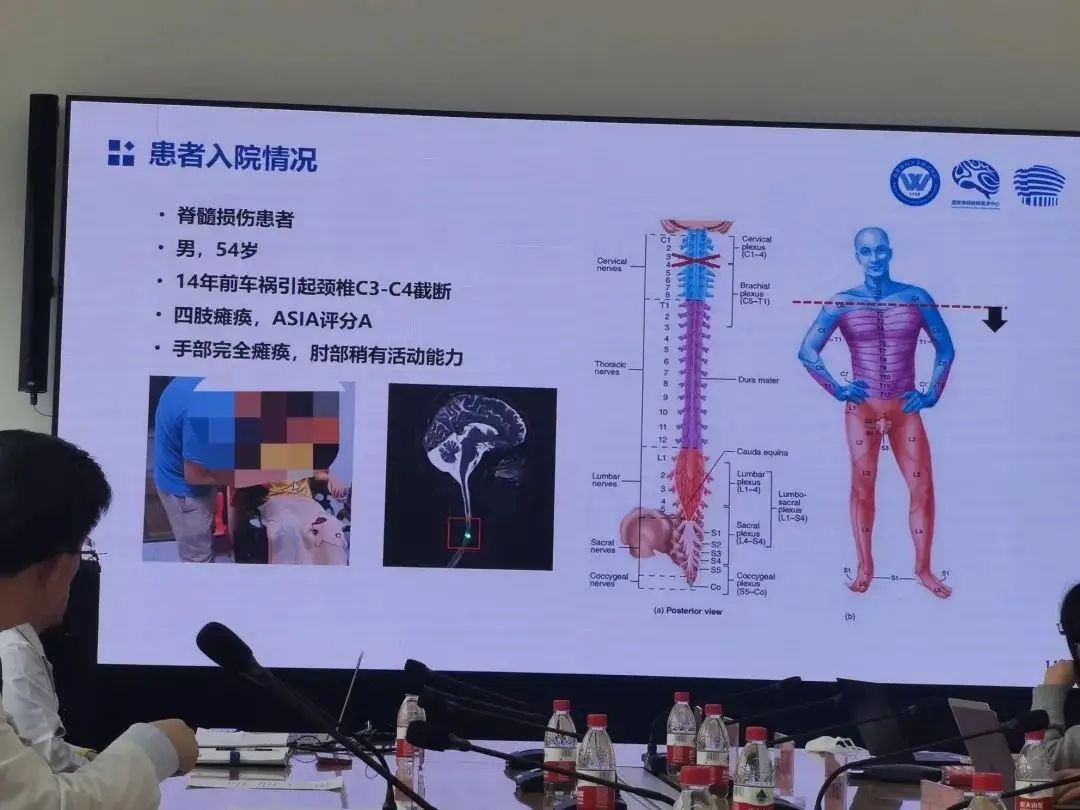 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技