
代做Multicore Computing、代写JAVA编程设计
2024.1 Multicore Computing, Project #1
(Due : April 18, 11:59pm)
Submission Rule
1. Create a directory "proj1". In the directory, create two subdirectories, “problem1” and
“problem2”.
2. In each of the directory “problem1” and “problem2”, Insert (i)JAVA source code, (ii)a document
that reports the parallel performance of your code, and (iii) video file (.mp4 format) that shows
compilation and execution of your code. You may use your smartphone camera or screen recorder
program to generate this video file. The document that reports the parallel performance should
contain (a) in what environment (e.g. CPU type, number of cores, memory size, OS type ...) the
experimentation was performed, (b) tables and graphs that show the execution time
(unit:milisecond) for the number of entire threads = {1,2,4,6,8,10,12,14,16,32}. (c) The
document should also contain explanation/analysis on the results and why such results are
obtained with sufficient details. (d) The document should also contain screen capture image of
program execution and output. In the document (i.e. report), you should briefly explain how to
compile and execute the source code you submit. You should use JAVA language.
3. zip the directory "proj1" into "proj1.zip" and submit the zip file into eClass homework board.
※ If possible, please experiment in a PC equipped with a CPU that has 4 or more cores.
problem 1. Following JAVA program (pc_serial.java) computes the number of ‘prime numbers’ between 1 and
200000 using a single thread.
(i) Implement multithreaded version of pc_serial.java using static load balancing (using block decomposition),
static load balancing (using cyclic decomposition), and dynamic load balancing. Submit the multithreaded JAVA
codes ("pc_static_block.java", "pc_static_cyclic.java" and "pc_dynamic.java"). Your program should
print the (1) execution time of each thread and (2) program execution time and (3) the number of ‘prime numbers’.
FYI, the static load balancing approach performs work division and task assignment while you do programming,
which means your program pre-determines which thread tests which numbers. A static load balancing approach can
use a block decomposition method or a cyclic decomposition method.
For example, assuming 4 threads and 200000 numbers, task assignment using
domain decomposition method: {0-49999}, {50000-99999}, {100000-149999}, {150000-199999}
cyclic decomposition method (task size: 10 numbers, which means each task-unit has 10 numbers): {1~10, 41~50,
81~90, ...} {11~20, 51~60, 91~100, ...}, {21~30, 61~70, 101~110, ...}, {31~40, 71~80, 111~120, ...}.
The dynamic load balancing approach assigns tasks to threads during execution time. For example, we may let each
thread take a number one by one and test whether the number is a prime number or not. (The recommended size
for one task is 10, which means each thread processes 10 numbers as one unit of task. However, you may choose
another task size if you think it would be better.
(ii) Write a document that reports and the parallel performance of your code. The graphs and tables that show the
execution time when using 1, 2, 4, 6, 8, 10, 12, 14, 16, 32 threads. You should include graphs, for static load
balancing (block), for static load balancing (cyclic), and for dynamic load balancing. Your document also should
mention which CPU type (dualcore? or quadcore?, hyperthreading on?, clock speed) was used for executing your
code. Your document should also include your interpretation of the parallel results.
exec time 1 2 4 ... 32
static (block)
static (cyclic)
[task size : 10
numbers]
dynamic
[task size : 10
numbers]
performace
(1/exec time)
1 2 4 ... 32
static (block)
static (cyclic)
[task size : 10
numbers]
dynamic
[task size : 10
numbers]
(iii) Create a demo video file (.mp4 format) that shows compilation and execution of your codes (Showing execution
using two threads and four threads for each of static(block), static(cyclic), and dynamic cases is enough for the
demo video file.). The size of the demo video file should be less than 30MB. (You may use KakaoTalk that
automatically reduces the video size when trying to transmit the video.)
Problem 2. (i) Given a JAVA source code for matrix multiplication (the source code MatmultD.java is available
on our class webpage), modify the JAVA code to implement parallel matrix multiplication that uses multi-threads.
You should use a static load balancing approach. You may choose either block decomposition method or cyclic
decomposition method. You may also choose the size of each task. Your program should print as output (1) the
execution time of each thread, (2) execution time when using all threads, and (3) sum of all elements in the
resulting matrix. Use the matrix mat500.txt (available on our class webpage) as file input (standard input) for the
performance evaluation. mat500.txt contains two matrices that will be used for multiplication.
command line execution example in cygwin terminal> java MatmultD 6 < mat500.txt
In eclipse, set the argument value and file input by using the menu [Run]->[Run Configurations]->{[Arguments],
[Common -> Input File].
Here, 6 means the number of threads to use, < mat500.txt means the file that contains two matrices is given as
standard input.
(ii) Write a document that reports the parallel performance of your code. The graph that shows the execution time
when using 1, 2, 4, 6, 8, 10, 12, 14, 16, 32 threads. Your document also should mention decomposition method
(block or cyclic?), task size, and CPU type (quadcore?, clock speed) that was used for executing your code.
1 2 4 ... 32
exec time
1 2 4 ... 32
performace
(1/exec time)
(iii) Create a demo video file (.mp4 format) that shows compilation and execution of your codes (showing execution
using two threads and four threads is enough for the demo video file.). The size of the demo video file should be
less than 30MB. (You may use KakaoTalk that automatically reduces the video size when trying to transmit the
video.)
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- AI服务器滑轨供应商南俊国际转盈
- Line群发软件一键推送,万众瞩目!我的Line群发云控工具心得分享:成功并非偶然,而是每一次明智的选择的积累
- ins群发软件,ins拉群软件联系天宇爆粉【TG:@cjhshk199937】
- ins群发软件/instagram群发软件,海外爆粉联系天宇预约测试
- Telegram群组活跃软件,TG自动化炒群工具,电报脚本炒群神器
- WhatsApp营销软件,ws自动养号/ws协议号/ws群发/咨询大轩
- 商标打擦边球、非法破解改装,半岛超声炮遭遇“李鬼”
- 新品新技术+豪华品牌+高端会议!2024广东水展整装待发,你想要的这儿都有!
- Ins引流推广软件,Instagram采集器一键助你博主打粉成功!
- EB5项目考察之行:世贸通移民集团因何受美国国会议员接见
- 2024上海暖通舒适系统展即将开幕,“暖通人”的行业年中盛会!
- 深化合作 共研共创 新点软件出席华为中国合作伙伴2024
- ODCC春季全会召开| 忆联持续5年以领先技术为ODCC项目研究提供支持
- 精准管理网络通信:Line协议号注册器助力工程师轻松分配标识
- 用户情感的调色盘WhatsApp拉群营销工具让每位用户都沉浸在美好的体验中
- 数字革命 WhatsApp拉群新功能引领市场热潮 我们的工具告诉你原因
- COMP9334代做、代写Python设计程序
- 你发现了这个WhatsApp拉群营销工具吗 一起来交流使用体验吧
- Instagram营销群发软件,Ins一键群发工具,助你实现营销梦想!
- ins营销软件,ins群发软件,联系天宇TG轻松日发百万条爆粉
- 陈丹感恩:恒兴33年,感恩一路有你
- ins拉群软件,ins群发软件,ins营销软件联系天宇爆粉【TG:@cjhshk199937】
- COMP9334代做、代写Python设计程序
- Ins引流新软件!Instagram自动聊天软件,ig多功能群发器!
- instagram社交爆发利器,一键群发采集,助你实现爆粉引流!
- 2024“蓉漂杯”大健康产业链主企业命题揭榜赛顺利举行!
- 眼科创新药物法瑞西单抗(罗视佳®)于北京爱尔英智眼科医院完成国内首批注射
- 创意驱动增长,Adobe护城河够深吗?
- 荣耀时刻丨公元两类管道产品入选国家首批专利密集型产品名单
- ins协议私信新玩法!Instagram引流新方式,Ins一键消息发送助你轻松推广!
推荐
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
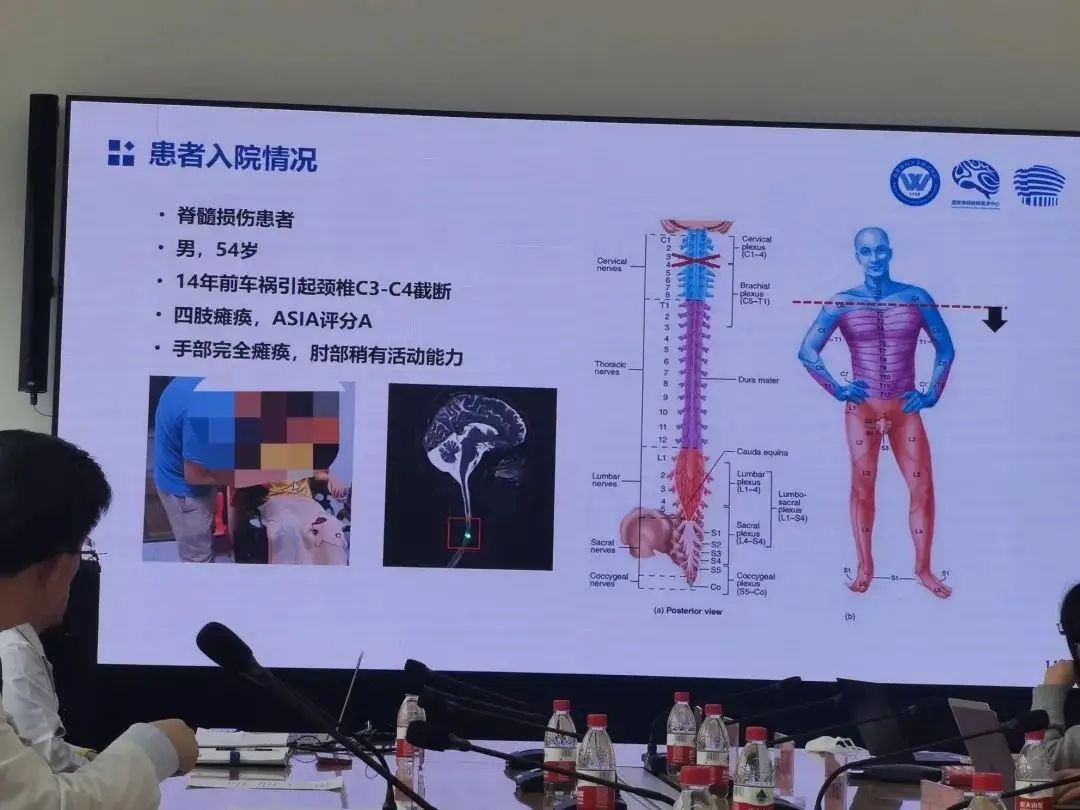 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技