
Ac.F633代做、Python程序语言代写
Ac.F633 - Python Programming Final Individual Project
Ac.F633 - Python Programming for Data Analysis
Manh Pham
Final Individual Project
20 March 2024 noon/12pm to 10 April 2024 noon/12pm (UK time)
This assignment contains one question worth 100 marks and constitutes 60% of the
total marks for this course.
You are required to submit to Moodle a SINGLE .zip folder containing a single Jupyter Notebook .ipynb file OR a single Python script .py file, together with
any supporting .csv files (e.g. input data files. However, do NOT include the
‘IBM 202001.csv.gz’ data file as it is large and may slow down the upload and submission) AND a signed coursework coversheet. The name of this folder should be
your student ID or library card number (e.g. 12345678.zip, where 12345678 is your
student ID).
In your answer script, either Jupyter Notebook .ipynb file or Python .py file, you
do not have to retype the question for each task. However, you must clearly label
which task (e.g. 1.1, 1.2, etc) your subsequent code is related to, either by using a
markdown cell (for .ipynb file) or by using the comments (e.g. #1.1 or ‘‘‘1.1’’’
for .py file). Provide only ONE answer to each task. If you have more than one
method to answer a task, choose one that you think is best and most efficient. If
multiple answers are provided for a task, only the first answer will be marked.
Your submission .zip folder MUST be submitted electronically via Moodle by the
10 April 2024 noon/12pm (UK time). Email submissions will NOT be considered. If you have any issues with uploading and submitting your work to Moodle,
please email Carole Holroyd at c.holroyd@lancaster.ac.uk BEFORE the deadline
for assistance with your submission.
The following penalties will be applied to all coursework that is submitted after the
specified submission date:
Up to 3 days late - deduction of 10 marks
Beyond 3 days late - no marks awarded
Good Luck!
1
Ac.F633 - Python Programming Final Individual Project
Question 1:
Task 1: High-frequency Finance (Σ = 30 marks)
The data file ‘IBM 202001.csv.gz’ contains the tick-by-tick transaction data for
stock IBM in January 2020, with the following information:
Fields Definitions
DATE Date of transaction
TIME M Time of transaction (seconds since mid-night)
SYM ROOT Security symbol root
EX Exchange where the transaction was executed
SIZE Transaction size
PRICE Transaction price
NBO Ask price (National Best Offer)
NBB Bid price (National Best Bid)
NBOqty Ask size
NBBqty Bid size
BuySell Buy/Sell indicator (1 for buys, -1 for sells)
Import the data file into Python and perform the following tasks:
1.1: Write code to perform the filtering steps below in the following order: (15 marks)
F1: Remove entries with either transaction price, transaction size, ask price,
ask size, bid price or bid size ≤ 0
F2: Remove entries with bid-ask spread (i.e. ask price - bid price) ≤ 0
F3: Aggregate entries that are (a) executed at the same date time (i.e. same
‘DATE’ and ‘TIME M’), (b) executed on the same exchange, and (c) of
the same buy/sell indicator, into a single transaction with the median
transaction price, median ask price, median bid price, sum transaction
size, sum ask size and sum bid size.
F4: Remove entries for which the bid-ask spread is more that 50 times the
median bid-ask spread on each day
F5: Remove entries with the transaction price that is either above the ask
price plus the bid-ask spread, or below the bid price minus the bid-ask
spread
Create a data frame called summary of the following format that shows the
number and proportion of entries removed by each of the above filtering steps.
The proportions (in %) are calculated as the number of entries removed divided
by the original number of entries (before any filtering).
F1 F2 F3 F4 F5
Number
Proportion
Here, F1, F2, F3, F4 and F5 are the columns corresponding to the above 5
filtering rules, and Number and Proportion are the row indices of the data
frame.
2
Ac.F633 - Python Programming Final Individual Project
1.2: Using the cleaned data from Task 1.1, write code to compute Realized
Volatility (RV), Bipower Variation (BV) and Truncated Realized Volatility
(TRV) measures (defined in the lectures) for each trading day in the sample
using different sampling frequencies including 1 second (1s), 2s, 3s, 4s, 5s, 10s,
15s, 20s, 30s, 40s, 50s, 1 minute (1min), 2min, 3min, 4min, 5min, 6min, 7min,
8min, 9min, 10min, 15min, 20min and 30min. The required outputs are 3
data frames RVdf, BVdf and TRVdf (for Realized Volatility, Bipower Variation
and Truncated Realized Volatility respectively), each having columns being
the above sampling frequencies and row index being the unique dates in the
sample. (10 marks)
1.3: Use results in Task 1.2, write code to produce a 1-by-3 subplot figure that
shows the ‘volatility signature plot’ for RV, BV and TRV. Scale (i.e. multiply)
the RVs, BVs and TRVs by 104 when making the plots. Your figure should
look similar to the following.
0 500 1000 1500
Sampling frequency (secs)
1.0
1.5
2.0
2.5
A
v
era
g
e
d
R
V (x10
4
)
RV signature plot
0 500 1000 1500
Sampling frequency (secs)
0.6
0.8
1.0
1.2
1.4
A
v
era
g
e
d
B
V (x10
4
)
BV signature plot
0 500 1000 1500
Sampling frequency (secs)
0.5
0.6
0.7
0.8
0.9
1.0
A
v
era
g
e
d
T
R
V (x10
4
)
TRV signature plot
(5 marks)
Task 2: Return-Volatility Modelling (Σ = 25 marks)
Refer back to the csv data file ‘DowJones-Feb2022.csv’ that lists the constituents of the Dow Jones Industrial Average (DJIA) index as of 9 February
2022 that was investigated in the group project. Import the data file into
Python.
Using your student ID or library card number (e.g. 12345678) as a random
seed, draw a random sample of 2 stocks (i.e. tickers) from the DJIA index
excluding stock DOW.1
Import daily Adjusted Close (Adj Close) prices for
both stocks between 01/01/2010 and 31/12/2023 from Yahoo Finance. Compute the log daily returns (in %) for both stocks and drop days with NaN
returns. Perform the following tasks.
2.1: Using data between 01/01/2010 and 31/12/2020 as in-sample data, write
code to find the best-fitted ARMA(p, q) model for returns of each stock that
minimizes AIC, with p and q no greater than 3. Print the best-fitted ARMA(p, q)
output and a statement similar to the following for your stock sample.
Best-fitted ARMA model for WBA: ARMA(2,2) - AIC = 11036.8642
Best-fitted ARMA model for WMT: ARMA(2,3) - AIC = 8810.4277 (5 marks)
1DOW only started trading on 20/03/2019
3
Ac.F633 - Python Programming Final Individual Project
2.2: Write code to plot a 2-by-4 subplot figure that includes the following diagnostics for the best-fitted ARMA model found in Task 2.1:
Row 1: (i) Time series plot of the standardized residuals, (ii) histogram of
the standardized residuals, fitted with a kernel density estimate and the
density of a standard normal distribution, (iii) ACF of the standardized
residuals, and (iv) ACF of the squared standardized residuals.
Row 2: The same subplots for the second stock.
Your figure should look similar to the following for your sample of stocks.
Comment on what you observe from the plots. (6 marks)
2010 2012 2014 2016 2018 2020
Date
8
6
4
2
0
2
4
6
ARMA(2,2) Standardized residuals-WBA
3 2 1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Density
Distribution of standardized residuals
N(0,1)
0 5 10 15 20 25 30 35
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00
ACF of standardized residuals
0 5 10 15 20 25 30 35
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00 ACF of standardized residuals squared
2010 2012 2014 2016 2018 2020
Date
7.5
5.0
2.5
0.0
2.5
5.0
7.5
ARMA(2,3) Standardized residuals-WMT
3 2 1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Density
Distribution of standardized residuals
N(0,1)
0 5 10 15 20 25 30 35
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00
ACF of standardized residuals
0 5 10 15 20 25 30 35
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00 ACF of standardized residuals squared
2.3: Use the same in-sample data as in Task 2.1, write code to find the bestfitted AR(p)-GARCH(p
∗
, q∗
) model with Student’s t errors for returns of each
stock that minimizes AIC, where p is fixed at the AR lag order found in
Task 2.1, and p
∗ and q
∗ are no greater than 3. Print the best-fitted AR(p)-
GARCH(p
∗
, q∗
) output and a statement similar to the following for your stock
sample.
Best-fitted AR(p)-GARCH(p*,q*) model for WBA: AR(2)-GARCH(1,1) - AIC
= 10137.8509
Best-fitted AR(p)-GARCH(p*,q*) model for WMT: AR(2)-GARCH(3,0) - AIC
= 7743.4547 (5 marks)
2.4: Write code to plot a 2-by-4 subplot figure that includes the following diagnostics for the best-fitted AR-GARCH model found in Task 2.3:
Row 1: (i) Time series plot of the standardized residuals, (ii) histogram of
the standardized residuals, fitted with a kernel density estimate and the
density of a fitted Student’s t distribution, (iii) ACF of the standardized
residuals, and (iv) ACF of the squared standardized residuals.
Row 2: The same subplots for the second stock.
Your figure should look similar to the following for your sample of stocks.
Comment on what you observe from the plots. (6 marks)
4
Ac.F633 - Python Programming Final Individual Project
2010 2012 2014 2016 2018 2020
Date
10.0
7.5
5.0
2.5
0.0
2.5
5.0
7.5
AR(2)-GARCH(1,1) Standardized residuals-WBA
3 2 1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Density
Distribution of standardized residuals
t(df=3.7)
0 5 10 15 20 25 30 35
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00
ACF of standardized residuals
0 5 10 15 20 25 30 35
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00 ACF of standardized residuals squared
2010 2012 2014 2016 2018 2020
Date
10
5
0
5
10
AR(2)-GARCH(3,0) Standardized residuals-WMT
3 2 1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
Density
Distribution of standardized residuals
t(df=3.9)
0 5 10 15 20 25 30 35
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00
ACF of standardized residuals
0 5 10 15 20 25 30 35
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00 ACF of standardized residuals squared
2.5: Write code to plot a 1-by-2 subplot figure that shows the fitted conditional
volatility implied by the best-fitted AR(p)-GARCH(p
∗
, q∗
) model found in
Task 2.3 against that implied by the best-fitted ARMA(p, q) model found in
Task 2.1 for each stock in your sample. Your figure should look similar to the
following.
2010
2012
2014
2016
2018
2020
Date
1
2
3
4
5
6
7
Fitted conditional volatility for stock WBA
AR(2)-GARCH(1,1)
ARMA(2,2)
2010
2012
2014
2016
2018
2020
Date
1
2
3
4
5
6
Fitted conditional volatility for stock WMT
AR(2)-GARCH(3,0)
ARMA(2,3)
(3 marks)
Task 3: Return-Volatility Forecasting (Σ = 25 marks)
3.1: Use data between 01/01/2021 and 31/12/2023 as out-of-sample data, write
code to compute one-step forecasts, together with 95% confidence interval
(CI), for the returns of each stock using the respective best-fitted ARMA(p, q)
model found in Task 2.1. You should extend the in-sample data by one observation each time it becomes available and apply the fitted ARMA(p, q) model
to the extended sample to produce one-step forecasts. Do NOT refit the
ARMA(p, q) model for each extending window.2 For each stock, the forecast
output is a data frame with 3 columns f, fl and fu corresponding to the
one-step forecasts, 95% CI lower bounds, and 95% CI upper bounds. (5 marks)
3.2: Write code to plot a 1-by-2 subplot figure showing the one-step return
forecasts found in Task 3.1 against the true values during the out-of-sample
2Refitting the model each time a new observation comes generally gives better forecasts. However,
it slows down the program considerably so we do not pursue it here.
5
Ac.F633 - Python Programming Final Individual Project
period for both stocks in your sample. Also show the 95% confidence interval
of the return forecasts. Your figure should look similar to the following.
2021-05
2021-09
2022-01
2022-05
2022-09
2023-01
2023-05
2023-09
Date
10.0
7.5
5.0
2.5
0.0
2.5
5.0
7.5
ARMA(2,2) One-step return forecasts - WBA
Observed
Forecasts
95% IC
2021-05
2021-09
2022-01
2022-05
2022-09
2023-01
2023-05
2023-09
Date
12.5
10.0
7.5
5.0
2.5
0.0
2.5
5.0
ARMA(2,3) One-step return forecasts - WMT
Observed
Forecasts
95% IC
(3 marks)
3.3: Write code to produce one-step analytic forecasts, together with 95%
confidence interval, for the returns of each stock using respective best-fitted
AR(p)-GARCH(p
∗
, q∗
) model found in Task 2.3. For each stock, the forecast
output is a data frame with 3 columns f, fl and fu corresponding to the
one-step forecasts, 95% CI lower bounds, and 95% CI upper bounds. (4 marks)
3.4: Write code to plot a 1-by-2 subplot figure showing the one-step return
forecasts found in Task 3.3 against the true values during the out-of-sample
period for both stocks in your sample. Also show the 95% confidence interval
of the return forecasts. Your figure should look similar to the following.
2021-05
2021-09
2022-01
2022-05
2022-09
2023-01
2023-05
2023-09
Date
15
10
5
0
5
10
15
AR(2)-GARCH(1,1) One-step return forecasts - WBA
Observed
Forecasts
95% IC
2021-05
2021-09
2022-01
2022-05
2022-09
2023-01
2023-05
2023-09
Date
15
10
5
0
5
10
15
AR(2)-GARCH(3,0) One-step return forecasts - WMT
Observed
Forecasts
95% IC (3 marks)
3.5: Denote by et+h|t = yt+h − ybt+h|t
the h-step forecast error at time t, which
is the difference between the observed value yt+h and an h-step forecast ybt+h|t
produced by a forecast model. Four popular metrics to quantify the accuracy
of the forecasts in an out-of-sample period with T
′ observations are:
1. Mean Absolute Error: MAE = 1
T′
PT
′
t=1 |et+h|t
|
2. Mean Square Error: MSE = 1
T′
PT
′
t=1 e
2
t+h|t
3. Mean Absolute Percentage Error: MAPE = 1
T′
PT
′
t=1 |et+h|t/yt+h|
4. Mean Absolute Scaled Error: MASE = 1
T′
PT
′
t=1
et+h|t
1
T′−1
PT′
t=2 |yt − yt−1|
.
6
Ac.F633 - Python Programming Final Individual Project
The closer the above measures are to zero, the more accurate the forecasts.
Now, write code to compute the four above forecast accuracy measures for
one-step return forecasts produced by the best-fitted ARMA(p,q) and AR(p)-
GARCH(p
∗
,q
∗
) models for each stock in your sample. For each stock, produce
a data frame containing the forecast accuracy measures of a similar format
to the following, with columns being the names of the above four accuracy
measures and index being the names of the best-fitted ARMA and AR-GARCH
model:
MAE MSE MAPE MASE
ARMA(2,2)
AR(2)-GARCH(1,1)
Print a statement similar to the following for your stock sample:
For WBA:
Measures that ARMA(2,2) model produces smaller than AR(2)-GARCH(1,1)
model:
Measures that AR(2)-GARCH(1,1) model produces smaller than ARMA(2,2)
model: MAE, MSE, MAPE, MASE. (5 marks)
3.6: Using a 5% significance level, conduct the Diebold-Mariano test for each
stock in your sample to test if the one-step return forecasts produced by the
best-fitted ARMA(p,q) and AR(p)-GARCH(p
∗
,q
∗
) models are equally accurate
based on the three accuracy measures in Task 3.5. For each stock, produce a
data frame containing the forecast accuracy measures of a similar format to
the following:
MAE MSE MAPE MASE
ARMA(2,2)
AR(2)-GARCH(1,1)
DMm
pvalue
where ‘DMm’ is the Harvey, Leybourne & Newbold (1997) modified DieboldMariano test statistic (defined in the lecture), and ‘pvalue’ is the p-value associated with the DMm statistic. Draw and print conclusions whether the bestfitted ARMA(p,q) model produces equally accurate, significantly less accurate
or significantly more accurate one-step return forecasts than the best-fitted
AR(p)-GARCH(p
∗
,q
∗
) model based on each accuracy measure for your stock
sample.
Your printed conclusions should look similar to the following:
For WBA:
Model ARMA(2,2) produces significantly less accurate one-step return
forecasts than model AR(2)-GARCH(1,1) based on MAE.
Model ARMA(2,2) produces significantly less accurate one-step return
forecasts than model AR(2)-GARCH(1,1) based on MSE.
Model ARMA(2,2) produces significantly less accurate one-step return
forecasts than model AR(2)-GARCH(1,1) based on MAPE.
Model ARMA(2,2) produces significantly less accurate one-step return
forecasts than model AR(2)-GARCH(1,1) based on MASE. (5 marks)
7
Ac.F633 - Python Programming Final Individual Project
Task 4: (Σ = 20 marks)
These marks will go to programs that are well structured, intuitive to use (i.e.
provide sufficient comments for me to follow and are straightforward for me
to run your code), generalisable (i.e. they can be applied to different sets of
stocks (2 or more)) and elegant (i.e. code is neat and shows some degree of
efficiency).
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- Telegram协议号安全性解析:如何保护网络通信的核心标识?
- 孟加拉#Telegram协议号-telegram劫持号-稳定耐用欢迎各大实力中介
- 时空商业的奇迹编织:zalo筛选器推广引发用户共鸣
- 贵州桃花源新型材料有限公司负氧离子黄晶板整装动静相宜,让人眼前一亮
- Instagram群发筛选软件,Ins群发注册工具,助你轻松推广!
- D-Day 杭州站 基于量化高频数据的极速投研实践
- 代做scheduled processor
- 国家重点研发计划“主动健康”专项课题终期验收会召开,神州医疗承担课题顺利通过验收
- 小土豆们一起穿越南北,品尔滨们YonSuite的魅力烟火
- 没用WhatsApp拉群工具之前 我的工作就像是一场无休无止的奔波
- 外贸新手看过来 WhatsApp拉群营销工具用哪个好 请大家分享一下经验
- 金i奖揭晓 | 谷器数据创始人石龙当选“工业软件2023年度人物”
- ins营销软件怎么自动群发私信?最稳instagram引流营销软件推荐
- 新突破!同仁堂健康冻干冬虫夏草(人工抚育)奢耀献市
- 一键Telegram代拉群,通过Telegram工具的精准推广,每个新客户都是一份生意上的喜悦福利
- Instagram群发筛选软件,Ins群发注册工具,助你轻松营销!
- 2024TCT亚洲3D打印展将于5月上海开幕丨展示最新成果,共享无限商机
- Instagram精准私信群发营销神器,Ins引流推广最新软件购买!
- instagram自动引流新招,ins一键打粉推广软件推荐
- 专业人士请教 WhatsApp拉群营销工具的使用经验 有人愿意分享吗
- 代筛全球app对营销有什么好处,跨境Telegram群发云控合约高手是否进入了智能合约的神秘境地
- WhatsApp源头机房出售协议号,ws群发必备工具推荐
- 外贸新手探索 WhatsApp拉群营销工具是如何激发我无尽好奇的
- Instagram精准营销软件,Ins自动引流助手,助你轻松提升业绩!
- Sora给制造企业数字化转型带来的启示
- Instagram群发消息工具,Ins模拟器群发软件,助你快速营销!
- CS 211编程代做、代写c/c++,Java程序
- Ins/Instagram全球引流神器,ins自动爆粉营销新境界!
- 广西美容养生:古韵今风,焕发自然之美
- 从冷冰冰到暖洋洋 新点软件助力内蒙古通辽政务数据“活起来”
推荐
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
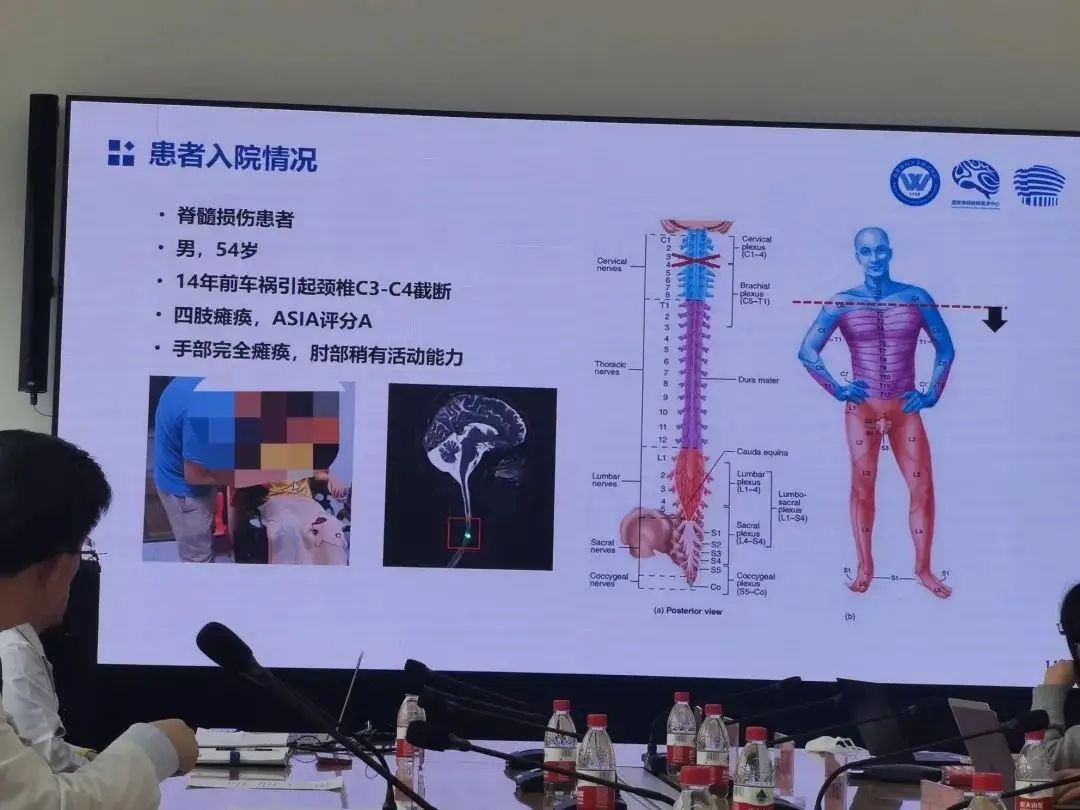 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技