
代写INAF U8145、代做c++,Java程序语言
SIPA INAF U8145
Spring 2024
Problem Set 3: Poverty and Inequality in Guatemala
Due Fri. April 5, 11:59pm, uploaded in a single pdf file on Courseworks
In this exercise, you will conduct an assessment of poverty and inequality in Guatemala. The data come from the
Encuesta de Condiciones de Vita (ENCOVI) 2000, collected by the Instituto Nacional de Estadistica (INE), the
national statistical institute of Guatemala, with assistance from the World Bank’s Living Standards Measurement
Study (LSMS). Information on this and other LSMS surveys are on the World Bank’s website at
http://www.worldbank.org/lsms. These data were used in the World Bank’s official poverty assessment for
Guatemala in 2003, available here.
Two poverty lines have been calculated for Guatemala using these ENCOVI 2000 data. The first is an extreme
poverty line, defined as the annual cost of purchasing the minimum daily caloric requirement of 2, 172 calories.
By this definition, the extreme poverty line is 1,912 Quetzals (Q), or approximately I$649 (PPP conversion), per
person per year. The second is a full poverty line, defined as the extreme poverty line plus an allowance for nonfood items, where the allowance is calculated from the average non-food budget share of households whose
calorie consumption is approximately the minimum daily requirement. (In other words, the full poverty line is the
average per-capita expenditures of households whose food per-capita food consumption is approximately at the
minimum.) By this definition, the full poverty line is 4,319 Q, or I$1,467.
Note on sampling design: the ENCOVI sample was not a random sample of the entire population. First, clusters
(or “strata”) were defined, and then households were sampled within each cluster. Given the sampling design, the
analysis should technically be carried out with different weights for different observations. Stata has a special set
of commands to do this sort of weighting (svymean, svytest, svytab etc.) But for the purpose of this exercise, we
will ignore the fact that the sample was stratified, and assign equal weight for all observations.1 As a result, your
answers will not be the same as in the World Bank’s poverty assessment, and will in some cases be unreliable.
1. Get the data. From the course website, download the dataset ps3.dta, which contains a subset of the variables
available in the ENCOVI 2000. Variable descriptions are contained in ps3vardesc.txt.
2. Start a new do file. My suggestion is that you begin again from the starter Stata program for Problem Set 1 (or
from your own code for Problem Set 1), keep the first set of commands (the “housekeeping” section) changing
the name of the log file, delete the rest, and save the do file under a new name.
3. Open the dataset in Stata (“use ps3.dta”), run the “describe” command, and check that you have 7,230
observations on the variables in ps3vardesc.txt.
4. Calculate the income rank for each household in the dataset (egen incrank = rank(incomepc)). Graph the
poverty profile. Include horizontal lines corresponding to the full poverty line and the extreme poverty line.
(Hint: you may want to create new variables equal to the full and extreme poverty lines.) When drawing the
poverty profile, only include households up to the 95th percentile in income per capita on the graph. (That is,
leave the top 5% of households off the graph.) Eliminating the highest-income household in this way will allow
you to use a sensible scale for the graph, and you will be able to see better what is happening at lower income
levels.
5. Using the full poverty line and the consumption per capita variable, calculate the poverty measures P0, P1, P2.
(Note: to sum a variable over all observations, use the command “egen newvar = total(oldvar);”.)
6. Using the extreme poverty line and the consumption per capita variable, again calculate P0, P1, and P2.
1 In all parts, you should treat each household as one observation. That is, do not try to adjust for the fact that
some households are larger than others. You will thus be calculating poverty statistics for households, using
per-capita consumption within the household as an indicator of the well-being of the household as a whole.
7. Using the full poverty line and the consumption per capita variable, calculate P2 separately for urban and rural
households.
8. Using the full poverty line and the consumption per capita variable, calculate P2 separately for indigenous and
non-indigenous households.
9. Using the full poverty line and the consumption per capita variable, calculate P2 separately for each region.
(Three bonus points for doing this in a “while” loop in Stata, like the one you used in Problem Set 1.)
10. Using one of your comparisons from parts 7-9, compute the contribution that each subgroup makes to
overall poverty. Note that if P2 is the poverty measure for the entire population (of households or of individuals),
and P2 j and sj are the poverty measure and population share of sub-group j of the population, then the
contribution of each sub-group to overall poverty can be written: sj*P2j/P2.
11. Summarize your results for parts 4-10 in a paragraph, noting which calculations you find particularly
interesting or important and why.
12. In many cases, detailed consumption or income data is not available, or is available only for a subset of
households, and targeting of anti-poverty programs must rely on poverty indices based on a few easy-toobserve correlates of poverty. Suppose that in addition to the ENCOVI survey, Guatemala has a population
census with data on all households, but suppose also that the census contains no information on per capita
consumption and only contains information on the following variables: urban, indig, spanish, n0_6, n7_24,
n25_59, n60_plus, hhhfemal, hhhage, ed_1_5, ed_6, ed_7_10, ed_11, ed_m11, and dummies for each region.
(In Stata, a convenient command to create dummy variables for each region is “xi i.region;”.) Calculate a
“consumption index” using the ENCOVI by (a) regressing log per-capita consumption on the variables
available in the population census, and (b) recovering the predicted values (command: predict), (c) converting
from log to level using the “exp( )” function in Stata. These predicted values are your consumption index. Note
that an analogous consumption index could be calculated for all households in the population census, using the
coefficient estimates from this regression using the ENCOVI data. Explain how.
13. Calculate P2 using your index (using the full poverty line) and compare to the value of P2 you calculated in
question 5.
14. Using the per-capita income variable, calculate the Gini coefficient for households (assuming that each
household enters with equal weight.) Some notes: (1) Your bins will be 1/N wide, where N is the number of
households. (2) The value of the Gini coefficient you calculate will not be equal to the actual Gini coefficient for
Guatemala, because of the weighting issue described above. (3) To generate a cumulative sum of a variable in Stata,
use the syntax “gen newvar = sum(oldvar);”. Try it out. (4) If you are interested (although it is not strictly
necessary in this case) you can create a difference between the value of a variable in one observation and the value
of the same variable in a previous observation in Stata, use the command “gen xdiff = x - x[_n-1];”. Be careful
about how the data are sorted when you do this.
What to turn in: In your write-up, you should report for each part any calculations you made, as well as written
answers to any questions. Remember that you are welcome to work in groups but you must do your write-up on
your own, and note whom you worked with. You should also attach a print-out of your Stata code.
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- 全球营销星际商务奇谭:Line群发云控工具是科技魔法的催化剂,引领我进入业务的星际时代
- WhatsApp拉群营销 新法宝
- 神州医疗弓孟春:基于多模态大数据的生成式AI为临床科研提供新质生产力
- instagram社交爆发神器,一键群发采集,助你快速引流!
- 打破创意瓶颈 WhatsApp拉群工具为你的消息注入新招数
- 解决广告费用问题 WhatsApp拉群工具助您实现精打细算广告成本
- WhatsApp美国协议号/ws印尼号/ws全球混合号/ws群发
- 代做COMP9334、Python/Java程序设计代写
- 绿色生态,健康之选——引领您走进生态农业的奇妙世界
- 网络工程精益求精:WhatsApp协议号注册器为您的项目提供支持
- 外贸的美妙奇遇 WhatsApp拉群营销工具如何点亮我的用户体验之旅
- 绿色国际:构建绿色生态,共创美好未来
- instagram群发引流利器,快速采集用户,助你实现社交爆发!
- 推动新质生产力发展,开年之际商越持续助力多家大中企业采购降本增效
- 鼎阳科技发布8GHz带宽12-bit高分辨率示波器,加速自身高端化进程
- 在腾讯2023年会上马化腾回应了64亿元在北京海淀区拿地的事情
- Ins/Instagram引流新秘籍,ins群发软件一键解锁精准营销!
- 数字夜航:科技魔法师的WhatsApp拉群营销工具,引发好奇的异次元冒险
- 精细化数据工艺:Line代筛料子专业团队为您打造一手数据精品
- 智能肿瘤学知识库启动 神州医疗以AI创新驱动医疗变革
- Instagram营销软件,ins定位采集工具/采集全球任意国家
- Telegram营销软件采集器,TG全自动群组采集软件,电报群成员采集利器
- 我曾陷入Zalo营销的迷失,直到遇到这个Zalo筛选器工具,找到了回家的路
- ins协议私信新玩法!Instagram引流新方式,Ins一键消息发送助你轻松推广!
- Instagram引流营销软件揭秘,Ins一键私信软件助你轻松爆粉!
- 四川速冻平台:让美食瞬间锁鲜,轻松品味四川风味
- 2024广东水展即将开幕 | 聚焦净水行业热点 抢占行业新机遇!
- Instagram官方引流打粉软件,Ins独家爆粉机器人震撼发布!
- 绿色国际:构建绿色生态,共创美好未来
- Instagram群发助手,ins引流如何普遍全球/ig私信工具
推荐
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
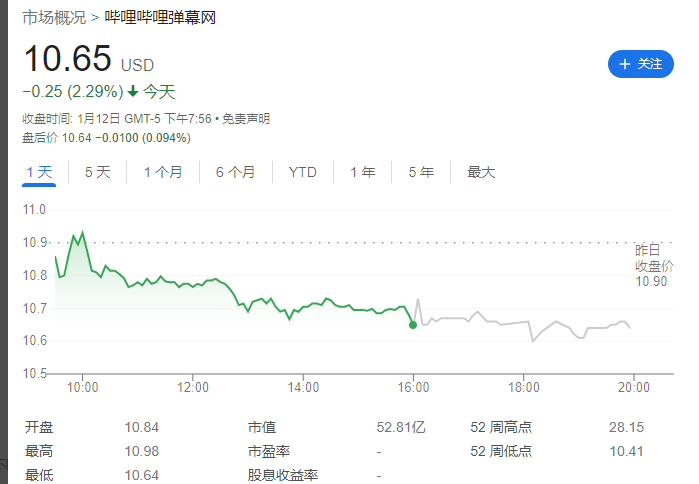 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
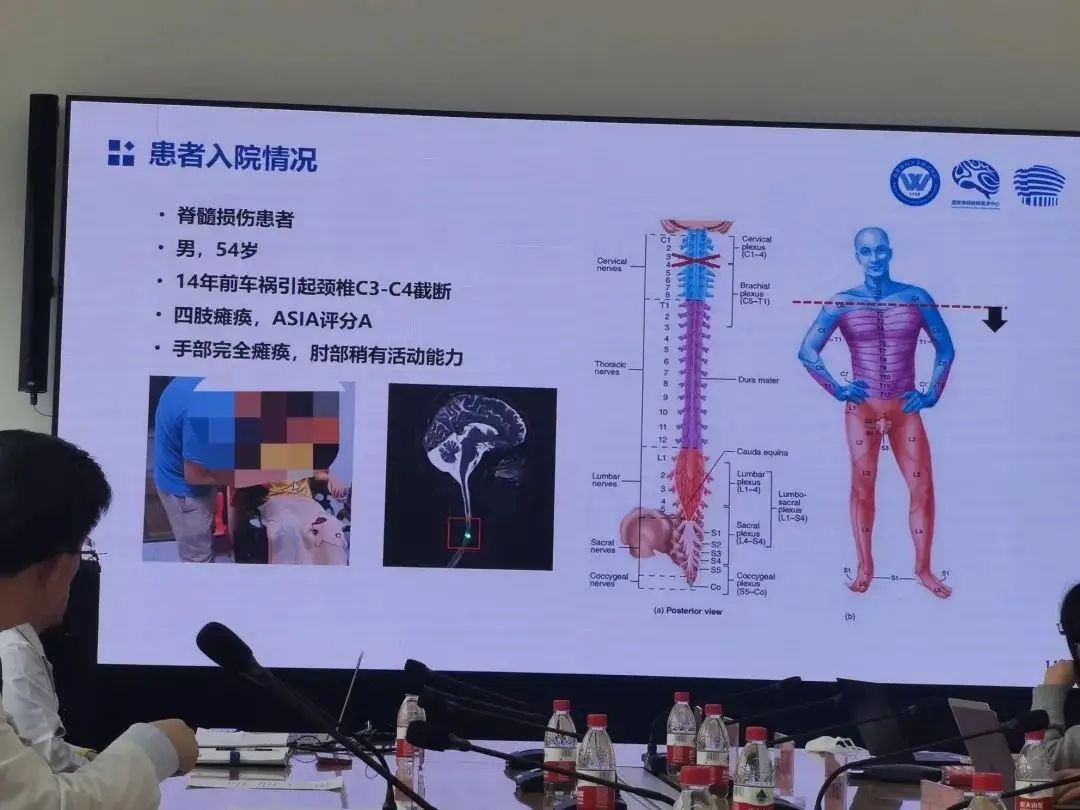 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技