
“曲线拟合+估值定价”,DolphinDB双引擎驱动 FICC 行业新发展
8月7日下午,DolphinDB 在南方科技大学举办了 D-Day 行业交流会深圳站,和二十余位 FICC 资深从业者一起深入探讨了驱动 FICC 市场发展的新型解决方案。DolphinDB 创始人周小华博士也来到现场,介绍了 DolphinDB 在 FICC 业务场景下的技术特点,以及曲线拟合引擎和估值定价引擎的研发构想。与会嘉宾积极参与,现场气氛热烈,活动取得圆满成功。
精英汇聚,共探 FICC 场景方案
DolphinDB 华南区销售总监赵胤首先介绍了 DolphinDB 在 FICC 场景下的两大主要应用:数据集市和策略投研。
与权益类数据相比,固收类数据虽然在量级上较小,但其数据类型的标准化程度较低,这会在数据清洗和使用过程中为用户带来一些挑战。为了解决这一问题,用户可以使用 DolphinDB 将非标准化的数据进行标准化处理,方便后续的投研和交易环节的数据处理与应用。同时,DolphinDB 有丰富的数据接口,可以接入不同交易所、不同数据源的实时或者历史数据,帮助客户解决数据同步的问题。这是 DolphinDB 在 FICC 场景下的基础实践。
在数据导入系统后,下一步就是策略投研。在这一环节,有的用户希望有一个集成式的投研平台,方便数据的统一管理和使用;有的用户希望仅将需要的功能纳入原有的投研体系,不造成冗余。DolphinDB 为不同需求的客户提供了搭建个性化策略投研平台的解决方案。基于在权益端投研平台建设方面的丰富经验,DolphinDB 在 FICC 场景下也抽象出了五大系统模块:估值定价、投资决策、头寸管理、风险分析、绩效分析。这五个模块覆盖了 FICC 常用业务场景,用户可以在 DolphinDB 一个系统中完成投研全流程。同时,这种模块化的设计也使用户能够选取自己需要的模块,便捷地将 DolphinDB 整合到现有的投研系统中。赵总监着重介绍了高频回测功能。目前,高频回测的痛点主要集中在速度慢以及数据回放方式的不灵活上,因此 DolphinDB 针对这两点打造了高性能高频回测功能。用 DolphinDB 进行回测的耗时相较于 Python 有明显优势,而且 DolphinDB 支持多种回放方式,用户可以自由设定时延、回放速率等。
赵总监还分享了几个客户实践的具体案例,包括券商做市交易策略监控、风险绩效系统建设、利率曲线拟合与实时指标计算以及国债期货 AI 算法交易全流程提速。研发提速10倍、查询提速10倍、计算效率提升100倍……这些指标都彰显了 DolphinDB 在 FICC 场景下的卓越性能。
创新突破,引擎释放数据潜能
随后,周博士登台为大家做了技术分享。他首先谈到了 DolphinDB 一贯以来的发展理念:把技术和业务融合起来,为客户创造价值。DolphinDB 努力打磨底层的技术框架,再结合行业研究推出一些标准化的业务中间件,最后倾听客户需求,和客户一起合作,落地真正适合客户的解决方案。
在这次交流会上,周博士详细介绍了与 FICC 业务密切相关的曲线拟合引擎和估值定价引擎。FICC 和权益类市场相比,信息流动性相对较弱,每家机构可能都有自己的一套运作体系,业内还在不断探索具有普适价值的解决方案。作为在金融行业深耕的基础软件,DolphinDB 希望通过提供这两个引擎来帮助机构在一定程度上优化 FICC 业务的数据分析流程。
在 FICC 业务中,收益率曲线拟合是至关重要的一个环节。所以 DolphinDB 在曲线拟合引擎中引入了很多常用的收益率曲线,用户可以直接调用。同时,该引擎也支持用户自定义目标函数,确保研究分析的灵活性。用户不需要通过写脚本来进行迭代,DolphinDB 会通过 JIT 技术直接将代码编译成机器码,加快研究进程。在得到收益率之后,用户可以接着调用估值定价引擎来对产品进行定价。DolphinDB 预置了多种定价方法,例如计算国债期货估值、利率互换估值、香草期权估值等等,用户可以按需调用。
除了 FICC 投研,客户在其他数据处理环节也有着不同的需求。例如,在数据存储环节,客户对不同类型数据的存储、索引和读取有着不同的要求。基于“为客户创造价值”的服务理念和多模态存储的架构理念,DolphinDB 将这些需求抽象成不同的引擎,供客户调用。例如,TSDB、OLAP 、主键存储引擎、VectorDB 等等。这些引擎让客户可以在 DolphinDB 一个系统中完成各类数据的存储和整合。
周博士表示:“通过提供一系列引擎,我们希望尽可能减少用户在技术层面的投入,而将精力聚焦于业务层面,在竞争激烈的市场中获得更大的优势。”
技术融合,打造企业级软件产品
除了分享对各类引擎的探索,周博士还讲解了 DolphinDB 的实时计算平台构建、生态打造和 AI 方面的应用。为了打造企业级产品,周博士也描述了未来将要研发的存算分离架构、声明式 API,以及多集群的管理、运维和监控。
最后,大家围绕如何利用数据分析来提升金融行业的服务质量和效率展开了激烈讨论,活动圆满落幕。

- 金矢留学对话萨里大学:环境安全,业界合作紧密,就业机会多
- Skechers推出高科技仓库,采用Hai Robotics自动化“货到人”系统
- 麦谷村液体沙拉实力入选广东省食品行业优秀新产品
- 比心APP携手BLG开启电竞星火计划,助力年轻人实现灵活就业
- 盛禧奥成功开发在生产过程中不含PFAS 添加剂的阻燃塑料
- 水石评级:古钱币价值新标尺,护航收藏与投资
- 农发行上党区支行:践行支农职责,全力推动业务发展
- 七站巡游 闪亮同行,张亮麻辣烫现身黑龙江2024夏季旅游推介会
- 银盛支付荣获2023年度大来收单业务“突出贡献奖”
- CORE伊士曼服务平台重磅发布CORE Pattern数字机裁功能,重新定义行业服务标准
- 使用二手推料离心机时需要注意一些操作和维护事项
- 失眠睡不着,步长青花瓷稳心颗粒让您舒睡一整晚!
- View韩国面部轮廓手术干货!想要动骨的速看!
- 九号公司2023年营收102亿元,境外营收占比47%,净利增长超32%
- 科华数据闪耀绿色工厂厂务大会,以创新驱动半导体行业高质量发展
- 追溯香迹 芬芳奇遇 法国娇兰携手品牌香水代言人王鹤棣共度巴黎惊喜之旅
- 霞智科技携旗下重要产品亮相2024 CCE清洁展,领航智能清洁
- 获客软件市场持续升温,企业如何借助科技力量精准锁定目标客户?
- 持续深化基地直采模式,钱大妈助消费者实现“榴莲自由”
- 推进血液与再生医学事业蓬勃发展——2024血液与再生医学大会在津成功举办
- Instagram自动化引流工具,ins全球粉丝采集软件,ig私信助手/Instagram协议号
- 中华健康养生之道:探寻传统智慧,塑造健康生活
- 和谐有趣 柏厨打造具有人文关怀的居住空间
- 第30届哈尔滨种博会提质升级,10月28-30日移师长春全新亮相!
- 春季养肝正当时,情绪低落,胃口不好考虑仲景逍遥丸
- 重要成果丨洁特生物参与制定的细胞培养残留检测新国标发布!
- 如何选择合适的PVC防水生产线
- Higround和Minecraft携手推出艺术作品以展现游戏独特魅力
- 「澳門銀河™」呈献:今天…is the Day 刘德华巡回演唱会2024 – 澳门站 惊喜官宣 开售在即
- 智高互联•破圈融合 | 泛家居全屋场景生态私董会3月19日举行
推荐
-
 海南大学生返校机票贵 有什么好的解决办法吗?
近日,有网友在“人民网领导留言板&rdqu
资讯
海南大学生返校机票贵 有什么好的解决办法吗?
近日,有网友在“人民网领导留言板&rdqu
资讯
-
 抖音直播“新红人”进攻本地生活领域
不难看出,抖音本地生活正借由直播向本地生活
资讯
抖音直播“新红人”进攻本地生活领域
不难看出,抖音本地生活正借由直播向本地生活
资讯
-
 私域反哺公域一周带火一家店!
三四线城市奶茶品牌茶尖尖两年时间做到GMV
资讯
私域反哺公域一周带火一家店!
三四线城市奶茶品牌茶尖尖两年时间做到GMV
资讯
-
 看新东方创始人俞敏洪如何回应董宇辉新号分流的?
(来源:中国证券报)
东方甄选净利润大幅下滑
资讯
看新东方创始人俞敏洪如何回应董宇辉新号分流的?
(来源:中国证券报)
东方甄选净利润大幅下滑
资讯
-
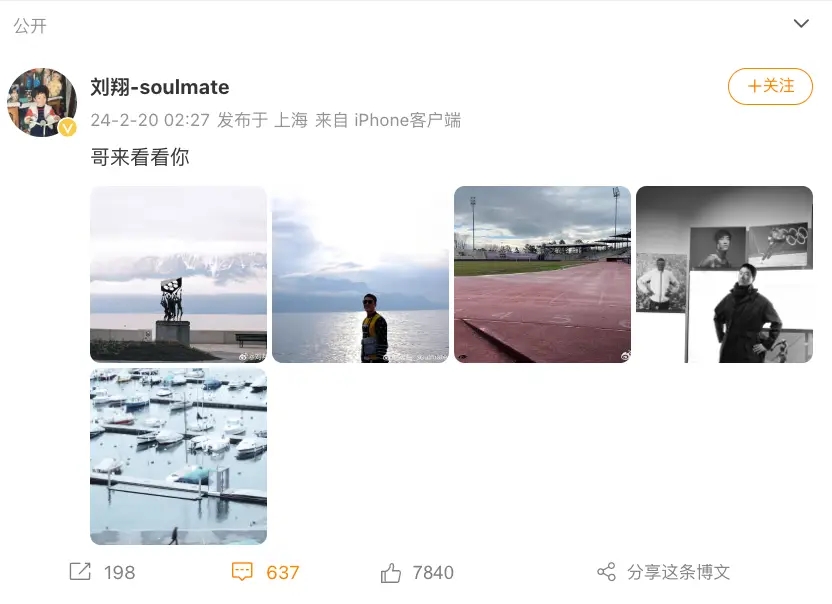 奥运冠军刘翔更新社交账号晒出近照 时隔473天更新动态!
2月20日凌晨2点,奥运冠军刘翔更新社交账号晒
资讯
奥运冠军刘翔更新社交账号晒出近照 时隔473天更新动态!
2月20日凌晨2点,奥运冠军刘翔更新社交账号晒
资讯
-
 产业数字化 为何需要一朵实体云?
改革开放前,国内供应链主要依靠指标拉动,其逻
资讯
产业数字化 为何需要一朵实体云?
改革开放前,国内供应链主要依靠指标拉动,其逻
资讯
-
 男子“机闹”后航班取消,同机旅客准备集体起诉
1月4日,一男子大闹飞机致航班取消的新闻登上
资讯
男子“机闹”后航班取消,同机旅客准备集体起诉
1月4日,一男子大闹飞机致航班取消的新闻登上
资讯
-
 周星驰新片《少林女足》在台湾省举办海选,吸引了不少素人和足球爱好者前来参加
周星驰新片《少林女足》在台湾省举办海选,吸
资讯
周星驰新片《少林女足》在台湾省举办海选,吸引了不少素人和足球爱好者前来参加
周星驰新片《少林女足》在台湾省举办海选,吸
资讯
-
 透过数据看城乡居民医保“含金量” 缴费标准是否合理?
记者从国家医保局了解到,近期,全国大部分地区
资讯
透过数据看城乡居民医保“含金量” 缴费标准是否合理?
记者从国家医保局了解到,近期,全国大部分地区
资讯
-
 一个“江浙沪人家的孩子已经不卷学习了”的新闻引发议论纷纷
星标★
来源:桌子的生活观(ID:zzdshg)
没
资讯
一个“江浙沪人家的孩子已经不卷学习了”的新闻引发议论纷纷
星标★
来源:桌子的生活观(ID:zzdshg)
没
资讯