
代写COMP7250、Python语言编程代做
Programming Assignment of COMP7250
Welcome to the assignment of COMP7250!
This assignment consists of two parts:
Part 1: Simple Classification with Neural Network
Part 2: Adversarial Examples for Neural Networks.
Through trying this assignment, you are expected to have a brief understanding on:
How to process data;
How to build a simple network;
The mechanisms of forward and backward propagation;
How to generate adversarial examples with FGSM and PGD methods.
Note that: although today we have powerful PyTorch to build up the deep learning piplines, in this
assignment, you are expected to use python and some fundamental packages like numpy to
realize the functions below and understand how it works.
TASK 1. Please realize an util function: one_hot_labels.
In the implementation of the cross entropy loss, it is much convenient if numerical labels are
transformed into one-hot labels.
For example, numerical label 5 -> one-hot label [0,0,0,0,0,1,0,0,0,0].
To begin with, MNIST dataset is loaded from the following files:
Note that, the original training images and labels are separated into a set of 50k data for training
and 10k data for validation.
import random
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
def one_hot_labels(labels):
one_hot_labels = np.zeros((labels.size, 10))
### YOUR CODE HERE
### END YOUR CODE
return one_hot_labels
images_train.npy: 60k images with normalized features, the dimension of image
features is 784.
images_test.npy
labels_train.npy: corresponding numerical labels (0-9).
labels_test.npy
TASK 2. Shuffle the data
As it is known to us, in order to avoid some potential factors that influence the learning process of
the model, shuffled data are preferred. Thus, please complete data by adding shuffle operations.
TASK 3. Please realize the softmax function as well as the sigmoid function: softmax(x) and
sigmoid(x).
The -th element of softmax is calculated via:
The last equation holds since adding a constant won't change softmax results. Note that, you may
encounter an overflow when softmax computes the exponential, so please using the 'max' tricks
to avoid this problem.
The sigmoid is calculated by:
For numerical stability, please use the 1st equation for positive inputs, and the 2nd equation for
negative inputs.
# Function for reading data&labels from files
def readData(images_file, labels_file):
x = np.load(images_file)
y = np.load(labels_file)
return x, y
def prepare_data():
trainData, trainLabels = readData('images_train.npy', 'labels_train.npy')
trainLabels = one_hot_labels(trainLabels)
### YOUR CODE HERE
### END YOUR CODE
valData = trainData[0:10000,:]
valLabels = trainLabels[0:10000,:]
trainData = trainData[10000:,:]
trainLabels = trainLabels[10000:,:]
testData, testLabels = readData('images_test.npy', 'labels_test.npy')
testLabels = one_hot_labels(testLabels)
return trainData, trainLabels, valData, valLabels, testData, testLabels
# load data for train, validation, and test.
trainData, trainLabels, devData, devLabels, testData, testLabels = prepare_data()
def softmax(x):
"""
x is of shape: batch_size * #class
"""
TASK 4. Please try to build a learning model according to the following instructions.
1. Complete the forward propagation function.
It is time to realize the forward propagation for a 2-layer neural network. Here, sigmoid is used as
the activation function, and the softmax is used as the link function. Formally,
hidden layer:
output layer:
loss:
Therein, are the outputs (before activation function) from the hidden layer and output layer;
, and are the learnable parameters. Concretely, and denote the weight
matrix and the bias vector for the hidden layer of the network. Similarly, and are the
weights and biases for the output layer. Note that, in computing the loss value, we should use
np.log(y+1e-16) instead of np.log(y) to avoid NaN (Not a Number) error in the case log(0).
2. Complete the calculation of gradients.
Based on the forward_pass function, you can implement the corresponding function for backward
propagation.
In order to help you have a better understanding of backward propagation process, please
calculate the gradients by hand first and complete the codes. (The gradients include the gradients
of , , , , , , .) Please present the calculation process in the cell below with
markdown.
Gradient Calculation Cell:
Please present the calculation process in this cell.
### YOUR CODE HERE
### END YOUR CODE
return s
def sigmoid(x):
"""
x is of shape: batch_size * dim_hidden
"""
### YOUR CODE HERE
### END YOUR CODE
return s
class Model(object):
def __init__(self, input_dim, num_hidden, output_dim, batchsize,
learning_rate, reg_coef):
'''
Args:
input_dim: int. The dimension of input features;
num_hidden: int. The dimension of hidden units;
output_dim: int. The dimension of output features;
TASK 5. Please complete the training procedure: nn_train(trainData, trainLabels, devData,
devLabels, **argv).
batchsize: int. The batchsize of the data;
learning_rate: float. The learning rate of the model;
reg_coef: float. The coefficient of the regularization.
'''
self.W1 = np.random.standard_normal((input_dim, num_hidden))
self.b1 = np.zeros((1, num_hidden), dtype=float)
self.W2 = np.random.standard_normal((num_hidden, output_dim))
self.b2 = np.zeros((1, output_dim))
self.reg_coef = reg_coef
self.bsz = batchsize
self.lr = learning_rate
def forward_pass(self, data, labels):
"""
return hidder layer, output(softmax) layer and loss
data is of shape: batch_size * dim_x
labels is of shape: batch_size * #class
"""
# YOUR CODE HERE
# END YOUR CODE
return h, y_hat, loss
def optimize_params(self, h, y_hat, data, labels):
# YOUR CODE HERE
# END YOUR CODE
if self.reg_coef > 0:
grad_W2 += self.reg_coef*self.W2
grad_W1 += self.reg_coef*self.W1
grad_W2 /= self.bsz
grad_W1 /= self.bsz
self.W1 -= self.lr * grad_W1
self.b1 -= self.lr * grad_b1
self.W2 -= self.lr * grad_W2
self.b2 -= self.lr * grad_b2
def calc_accuracy(y, labels):
"""
return accuracy of y given (true) labels.
"""
pred = np.zeros_like(y)
pred[np.arange(y.shape[0]), np.argmax(y, axis=1)] = 1
res = np.abs((pred - labels)).sum(axis=1)
acc = res[res == 0].shape[0] / res.shape[0]
return acc
As a convention, parameters should be randomly initialized with standard gaussian
variables, and parameters should initialized by 0. You can run nn_train with different values
of the hyper-parameter reg_strength to validate the impact of the regularization to the network
performance (e.g. reg_strength=0.5).
After training, we can plot the training and validation loss/accuracy curves to assess the model and
the learning procedure.
def nn_train(trainData, trainLabels, devData, devLabels,
num_hidden=300, learning_rate=5, batch_size=1000, num_epochs=30,
reg_strength=0):
(m, n) = trainData.shape
params = {}
N = m
D = n
K = trainLabels.shape[1]
H = num_hidden
B = batch_size
model = Model(input_dim=n, num_hidden=H, output_dim=K,
batchsize=B, learning_rate=learning_rate,
reg_coef=reg_strength)
num_iter = int(N / B)
tr_loss, tr_metric, dev_loss, dev_metric = [], [], [], []
for i in tqdm(range(num_epochs)):
for j in range(num_iter):
batch_data = trainData[j * B: (j + 1) * B]
batch_labels = trainLabels[j * B: (j + 1) * B]
### YOUR CODE HERE
### END YOUR CODE
_, _y, _cost = model.forward_pass(trainData, trainLabels)
tr_loss.append(_cost)
tr_metric.append(calc_accuracy(_y, trainLabels))
_, _y, _cost = model.forward_pass(devData, devLabels)
dev_loss.append(_cost)
dev_metric.append(calc_accuracy(_y, devLabels))
return model, tr_loss, tr_metric, dev_loss, dev_metric
num_epochs = 30
model, tr_loss, tr_metric, dev_loss, dev_metric = nn_train(
trainData, trainLabels, devData, devLabels, num_epochs=num_epochs)
xs = np.arange(num_epochs)
fig, axes = plt.subplots(1, 2, sharex=True, sharey=False, figsize=(12, 4))
ax0, ax1 = axes.ravel()
ax0.plot(xs, tr_loss, label='train loss')
ax0.plot(xs, dev_loss, label='dev loss')
Finally, we should evaluate the model performance on test data.
Part 2: Adversarial Examples for Neural Networks
It has been seen that many classifiers, including neural networks, are highly susceptible to what
are called adversarial examples -- small perturbations of the input that cause a classifier to
misclassify, but are imperceptible to humans. For example, making a small change to an image of
a stop sign might cause an object detector in an autonomous vehicle to classify it as an yield sign,
which could lead to an accident.
In this part, we will see how to construct adversarial examples for neural networks, and you
are given a 3-hidden layer perceptron trained on the MNIST dataset for this purpose.
Since we are interested in constructing the countersample rather than the original classification
task, we do not need to worry too much about the design of the neural network and the
processing of the data (which are already given). The parameters of the perceptron can be loaded
from fc*.weight,npy and fc*.bias.npy. The test dataset can be loaded from X_test.npy and
Y_test.npy. Each image of MNIST is 28×28 pixels in size, and is generally represented as a flat
vector of 784 numbers. It also includes labels for each example, a number indicating the actual
digit (0 - 9) handwritten in that image.
Enjoy practicing generating adversarial examples and have fun!
First, we need to define some functions for later computing.
TASK 1. Please realize the following functions:
relu: The relu function is calculated as:
ax0.legend()
ax0.set_xlabel('# epoch')
ax0.set_ylabel('CE loss')
ax1.plot(xs, tr_metric, label='train acc')
ax1.plot(xs, dev_metric, label='dev acc')
ax1.legend()
ax1.set_xlabel('# epoch')
ax1.set_ylabel('Accuracy')
plt.show()
def nn_test(data, labels):
h, output, cost = model.forward_pass(data, labels)
accuracy = accuracy = (np.argmax(output,axis=1) ==
np.argmax(labels,axis=1)).sum() * 1. / labels.shape[0]
return accuracy
accuracy = nn_test(testData, testLabels)
print('Test accuracy: {0}'.format(accuracy))
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
relu_grad: The relu_grad is used to compute the gradient of relu function as:
Next, we define the structure and some utility functions of our multi-layer perceptron.
The neural net is a fully-connected multi-layer perceptron with three hidden layers. The hidden
layers contains 2048, 512 and 512 hidden nodes respectively. We use ReLU as the activation
function at each hidden node. The last intermediate layer’s output is passed through a softmax
function, and the loss is measured as the cross-entropy between the resulted probability vector
and the true label.
def relu(x):
'''
Input
x: a vector in ndarray format
Output
relu_x: a vector in ndarray format,
representing the ReLu activation of x.
'''
### YOUR CODE HERE
### END YOUR CODE
return relu_x
def relu_grad(x):
'''
Input
x: a vector in ndarray format
Output
relu_grad_x: a vector in ndarray format,
representing the gradient of ReLu activation.
'''
### YOUR CODE HERE
### END YOUR CODE
return relu_grad_x
def cross_entropy(y, y_hat):
'''
Input
y: an int representing the class label
y_hat: a vector in ndarray format showing the predicted
probability of each class.
Output
the cross entropy loss.
'''
etp = one_hot_labels(y)*np.log(y_hat+1e-16)
loss = -np.sum(etp)
return loss
TASK 2. Please realize the forward propogation and the gradient calculation:
The forward propagation rules are as follows.
The gradient calculation rules are as follows.
Let L denote the cross entropy loss of an image-label pair (x, y). We are interested in the gradient
of L w.r.t. x, and move x in the direction of (the sign of) the gradient to increase L. If L becomes
large, the new image x_adv will likely be misclassified.
We use chain rule for gradient computation. Again, let h0 be the alias of x. We have:
The intermediate terms can be computed as follows.
TASK 3. Please generate the & adversarial examples based on the gradient.
We begin with deriving a simple way of constructing an adversarial example around an input (x, y).
Supppose we denote our neural network by a function f: X {0,...,9}.
Suppose we want to find a small perturbation of x such that the neural network f assigns a label
different from y to x+ . To find such a , we want to increase the cross-entropy loss of the
network f at (x, y); in other words, we want to take a small step along which the cross-entropy
loss increases, thus causing a misclassification. We can write this as a gradient ascent update, and
to ensure that we only take a small step, we can just use the sign of each coordinate of the
gradient. The final algorithm is this:
x: the input image vector with dimension 1x784.
y: the true class label of x.
zi: the value of the i-th intermediate layer before activation, with dimension
1x2048, 1x512, 1x512 and 1x10 for i = 1, 2, 3, 4.
hi: the value of the i-th intermediate layer after activation, with dimension
1x2048, 1x512 and 1x512 for i = 1, 2, 3.
p: the predicted class probability vector after the softmax function, with
dimension 1x10.
Wi: the weights between the (i - 1)-th and the i-th intermediate layer. For
simplicity, we use h0 as an alias to x. Each Wi has dimension li_1 x li, where li
is the number of nodes in the i-th layer. For example, W1 ha dimension 784x2048.
bi: the bias between the (i - 1)-th and the i-th intermediate layer. The
dimension is 1 x li.
where L is the cross-entropy loss, and it is known as the Fast Gradient Sign Method (FGSM).
From the angle of image processing, digital images often use only 8 bits per pixel, so they discard
all information below of the dynamic range. Because the precision of the feeatures is limited,
it is not rational for the classifier to respond differently to an input than to an adversarial input if
every element of the perturbation is smaller than the precision of the features. Thus, it is expected
that both original input and adversarial input are assigned to the same class if the perturbation
satistifies . In practical, the constraint is applied
as:
Please apply this constraint on the algorithm.
As shown above, FGSM is a single-step scheme. Next, we would like to introduce a multi-step
scheme, assignmented Gradient Descent(PGD).
Different from FGSM, PGD takes several steps for more powerful adversarial examples:
Specifically, first initializing with x.
Then, for each step, the following operations are conducted:
Compute the loss ;
Compute the gradients of input : ;
Normalize the gradients above with -Norm;
Generate intermediate adversaray:
Normalize the with the perturbation 's -Norm:
Get the adversarial example:
Apply the constraint on the adversary.
class MultiLayerPerceptron():
'''
This class defines the multi-layer perceptron we will be using
as the attack target.
'''
def __init__(self):
pass
def load_params(self, params):
'''
This method loads the weights and biases of a trained model.
'''
self.W1 = params["fc1.weight"]
self.b1 = params["fc1.bias"]
self.W2 = params["fc2.weight"]
self.b2 = params["fc2.bias"]
self.W3 = params["fc3.weight"]
self.b3 = params["fc3.bias"]
self.W4 = params["fc4.weight"]
self.b4 = params["fc4.bias"]
def set_attack_budget(self, eps):
'''
This method sets the maximum L_infty norm of the adversarial
perturbation.
'''
self.eps = eps
def forward(self, x):
'''
This method finds the predicted probability vector of an input
image x.
Input
x: a single image vector in ndarray format
Ouput
self.p: a vector in ndarray format representing the predicted class
probability of x.
Intermediate results are stored as class attributes.
You might need them for gradient computation.
'''
W1, W2, W3, W4 = self.W1, self.W2, self.W3, self.W4
b1, b2, b3, b4 = self.b1, self.b2, self.b3, self.b4
self.z1 = np.matmul(x,W1)+b1
#######################################
### YOUR CODE HERE
### END YOUR CODE
#######################################
return self.p
def predict(self, x):
'''
This method takes a single image vector x and returns the
predicted class label of it.
'''
res = self.forward(x)
return np.argmax(res)
def gradient(self,x,y):
'''
This method finds the gradient of the cross-entropy loss
of an image-label pair (x,y) w.r.t. to the image x.
Input
x: the input image vector in ndarray format
y: the true label of x
Output
grad: a vector in ndarray format representing
the gradient of the cross-entropy loss of (x,y)
w.r.t. the image x.
'''
#######################################
### YOUR CODE HERE
### END YOUR CODE
#######################################
return grad
def attack(self, x, y, attack_mode, epsilon, alpha=2./255.):
'''
This method generates the adversarial example of an
image-label pair (x,y).
Input
x: an image vector in ndarray format, representing
the image to be corrupted.
y: the true label of the image x.
attack_mode: str. Choice of the mode of attack. The mode can be
selected from ['no_constraint', 'L-inf', 'L2'];
epsilon: float. Hyperparameter for generating perturbations;
pgd_steps: int. Number of steps for running PGD algorithm;
alpha: float. Hyperparameter for generating adversarial examples in
each step of PGD;
Output
x_adv: a vector in ndarray format, representing
the adversarial example created from image x.
'''
#######################################
if attack_mode == 'L-inf':
### YOUR CODE HERE
### END YOUR CODE
elif attack_mode == 'L2':
### YOUR CODE HERE
### END YOUR CODE
elif attack_mode == 'no_constraint':
### YOUR CODE HERE
### END YOUR CODE
else:
raise ValueError("Unrecognized attack mode, please choose from ['Linf', 'L2'].")
#######################################
return x_adv
Now, let's load the test data and the pre-trained model.
Check if the image data are loaded correctly. Let's visualize the first image in the data set.
Check if the model is loaded correctly. The test accuracy should be 97.6%
TASK 4. Please generate adversarial examples and check the image.
Generate an FGSM adversarial example with (without constraint).
Generate an PGD adversarial example with (with constraint).
TASK 5. Try the adversarial attack and test the accuracy of using PGD adversarial examples.
X_test = np.load("./X_test.npy")
Y_test = np.load("./Y_test.npy")
params = {}
param_names = ["fc1.weight", "fc1.bias",
"fc2.weight", "fc2.bias",
"fc3.weight", "fc3.bias",
"fc4.weight", "fc4.bias"]
for name in param_names:
params[name] = np.load("./"+name+'.npy')
clf = MultiLayerPerceptron()
clf.load_params(params)
x, y = X_test[0], Y_test[0]
print ("This is an image of Number", y)
pixels = x.reshape((28,28))
plt.imshow(pixels,cmap="gray")
nTest = 1000
Y_pred = np.zeros(nTest)
for i in tqdm(range(nTest)):
x, y = X_test[i][np.newaxis, :], Y_test[i]
Y_pred[i] = clf.predict(x)
acc = np.sum(Y_pred == Y_test[:nTest])*1.0/nTest
print ("Test accuracy is", acc)
### Output pixels: an FGSM adversarial example with eps=0.1 (without constraint).
### YOUR CODE HERE
### END YOUR CODE
plt.imshow(pixels,cmap="gray")
### Output pixels: a PGD adversarial example with eps=8/255 (L_2 constraint).
### YOUR CODE HERE
### END YOUR CODE
plt.imshow(pixels,cmap="gray")
You can get a test accuracy of using adversarial examples after running this cell. (Please use 1000
test samples)
### Output acc: the adversarial accuracy.
### YOUR CODE HERE
### END YOUR CODE
print ("Test accuracy of adversarial examples is", acc)
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- 群发智能升级 专业海外营销者分享 WhatsApp拉群工具如何应对风控挑战 提升业务成绩
- Instagram采集器,ins自动化精准采集博主工具震撼登场!
- 代写CSci 4061 MultiThreaded Image
- 埃及#Telegram协议号-telegram劫持号-稳定耐用量大价稳!Line群发云控助您从容面对大规模推广任务
- 数环通入选中国信通院《高质量数字化转型技术方案集(2023)》,积极推动企业数字化转型
- 西部数据通过ASPICE CL3评估认证,满足汽车行业不断变化的需求
- pCloud以巨大折扣庆祝农历新年
- 进入元宇宙,体验令人惊叹的新东京 - The Virtual Edo-Tokyo Project (虚拟江户东京项目)
- 使用Line协议号星际商务奇谭:LINE工具是科技魔法的催化剂,引领我进入业务的星际时代
- 葡萄牙黄金居留计划基金移民:获欧盟身份的金钥匙
- Ins群发脚本助手,Instagram一键群发工具,让你打造营销新格局!
- WhatsApp群发营销工具,ws协议号/ws劫持号/ws拉群工具
- 多伦科技董事长章安强受邀出席中国电动汽车百人会论坛并作主题演讲
- “情系老党员,关怀送温暖”铭泰产业园党支部春节慰问贫困老党员
- 爱尔英智眼科医院李秋梅提醒,警惕“视力的小偷”——青光眼!
- 保险行业excel在线共享解决方案,魔方网表
- Instagram群发筛选营销软件,Ins群发注册工具,一键助你轻松推广!
- 中国电化铝网:行业先锋,引领电化铝新时代
- 莱特波特(LitePoint)与研华科技(Advantech)利用无线设计服务改变物联网(IoT)发展
- instagram深度推广引流营销软件,ins自动化群发助手
- Telegram群发引流大师,高效采集用户,助你轻松拉群!
- Ins高效筛选助手,Instagram群发代发工具,让你的营销更高效!
- 特色文旅平台.手机推动文化旅游业的发展
- Blue Yonder收购制造和供应链规划技术领先企业Flexis
- 一键Line代群发,品牌推广你会体会到无尽的喜悦之情
- 代写small-cap bio stocks程序
- ins拉群软件,ins群发软件,ins营销软件联系天宇爆粉【TG:@cjhshk199937】
- 并购重组税收政策(归纳)
- 构建智能投诉管理平台,让金融消费者权益保护更上层楼
- 在这个科技日新月异的时代 电子魅影 一位科技魔法师 凭借着他的WhatsApp拉群战略 犹如一道闪电 瞬间惊醒了市场巨兽
推荐
-
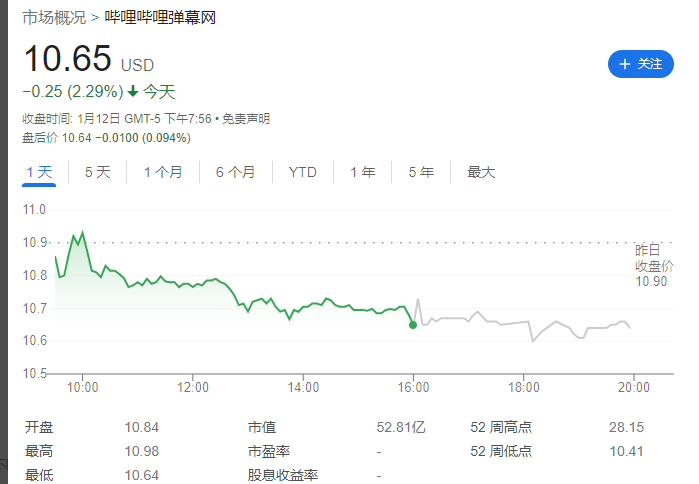 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
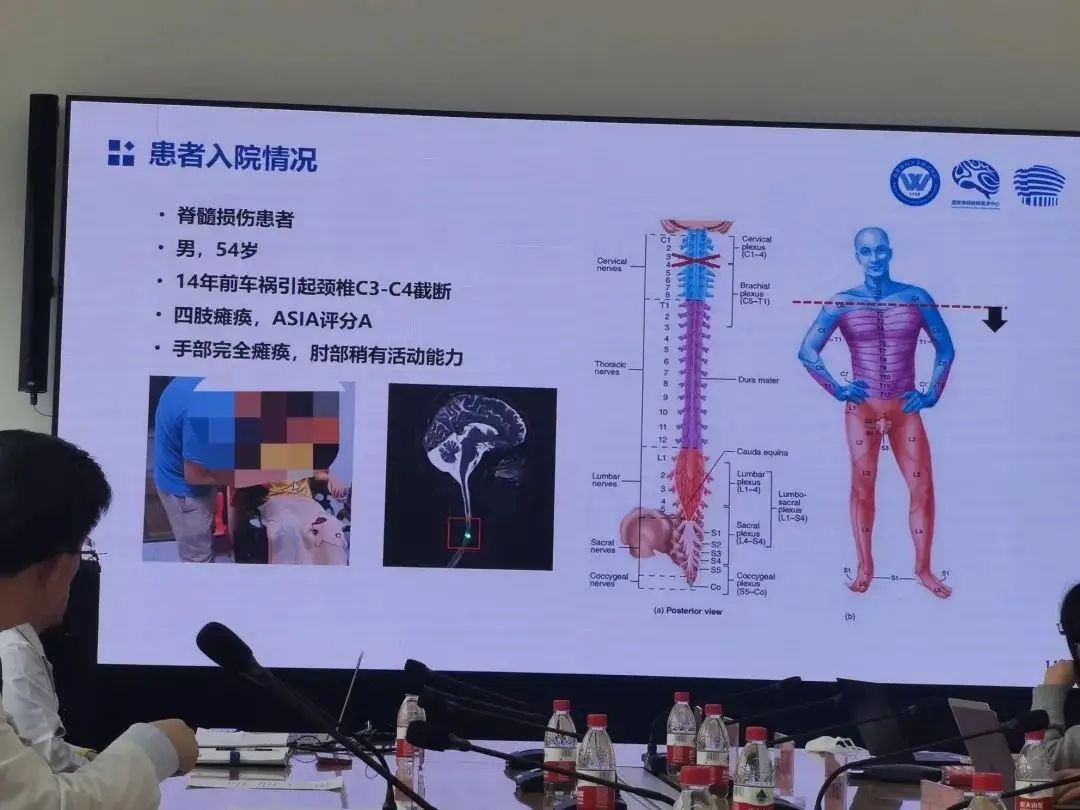 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技