
COMP3310代做、代写C++, Java/Python编程
Page 1 of 3
COMP3310 - Assignment 2: Indexing a Gopher.
Background:
• This assignment is worth 12.5% of the final mark.
• It is due by 23:55 Friday 26 April AEST (end of Week 8)
• Late submissions will not be accepted, except in special circumstances.
o Extensions must be requested as early as possible before the due date, with suitable
evidence or justification.
• If you would like feedback on particular aspects of your submission, please note that in the
README file within your submission.
This is a coding assignment, to enhance and check your network programming skills. The main focus is on
native socket programming, and your ability to understand and implement the key elements of an
application protocol from its RFC specification.
Please note that this is an ongoing experiment for the course, trialling gopher for this assignment. We may
discover some additional challenges as we go, that requires some adjustments to the assignment activities, or
a swap of server. Any adjustments will be noted via a forum Announcement.
Assignment 2 outline
An Internet Gopher server was one of the precursors to the web, combining a simple query/response
protocol with a reasonably flexible content server, and a basic model for referencing and describing
resources on different machines. The name comes from the (Americanised) idea to “go-for” some content…
and also the complexity of their interconnected burrows1
.
For this assignment, you need to write your own gopher client in C, Java or Python2,3
, without the use of any
external gopher-related libraries. The client will need to ‘spider’ or ‘crawl’ or ‘index’ a specified server, do
some simple analysis and reporting of what resources are there, as well as detect, report and deal with any
issues with the server or its content.
Your code MUST open sockets in the standard socket() API way, as per the tutorial exercises. Your code
MUST make appropriate and correctly-formed gopher requests on its own, and capture/interpret the results
on its own. You will be handcrafting gopher protocol packets, so you’ll need to understand the structures of
requests/responses as per the gopher RFC 1436.
We will provide a gopher server to run against, with a mix of content – text and binary files, across some
folder structure, along with various pointers to resources.
In the meantime, you SHOULD install a gopher server on your computer for local access, debugging and
wiresharking. There are a number available, with pygopherd perhaps the more recently updated but more
complex, and Motsognir, which is a bit older but simpler. If you find another good one, please share on the
forum.
1 https://en.wikipedia.org/wiki/Gopher
2 As most high-performance networking servers, and kernel networking modules, are written in C with other languages
a distant second, it is worth learning it. But, time is short, and everyone has a different background.
3
If you want to use another language (outside of C/Java/Python), discuss with your tutor – it has to have native socket
access, and somebody on the tutoring team has to be able to mark it.
Page 2 of 3
Wireshark will be very helpful for debugging purposes. A common trap is not getting your line-ending right on
requests, and this is rather OS and language-specific. Remember to be conservative in what you send and
reasonably liberal in what you accept.
What your successful and highly-rated indexing client will need to do:
1. Connect to the class gopher server, and get the initial response.
a. Wireshark (just) this initial-response conversation in both directions, from the starting TCP
connection to its closing, and include that wireshark summary in your README.
b. The class gopher site is not yet fully operational, an announcement will be made when it’s ready.
2. Starting with the initial response, automatically scan through the directories on the server, following links
to any other directories on the same server, and download any text and binary (non-text) files you find.
The downloading allows you to measure the file characteristics. Keep scanning till you run out of
references to visit. Note that there will be items linked more than once, so beware of getting stuck in a
loop.
3. While running, prints to STDOUT:
a. The timestamp (time of day) of each request, with
b. The client-request you are sending. This is good for debugging and checking if something gets
stuck somewhere, especially when dealing with a remote server.
4. Count, possibly store, and (at the end of the run) print out:
a. The number of Gopher directories on the server.
b. The number, and a list of all simple text files (full path)
c. The number, and a list of all binary (i.e. non-text) files (full path)
d. The contents of the smallest text file.
e. The size of the largest text file.
f. The size of the smallest and the largest binary files.
g. The number of unique invalid references (those with an “error” type)
h. A list of external servers (those on a different host and/or port) that were referenced, and
whether or not they were "up" (i.e. whether they accepted a connection on the specified port).
i. You should only connect to each external server (host+port combination) once. Don't
crawl their contents! We only need to know if they're "up" or not.
i. Any references that have “issues/errors”, that your code needs to explicitly deal with.
Requests that return errors, or that had to abort (e.g. due to a timeout, or for any other reason) do not count
towards the number of (smallest/largest)(text/binary) files.
You will need to keep an eye on your client while it runs, as some items might be a little challenging if you’re
not careful… Not every server provides perfectly formed replies, nor in a timely fashion, nor properly
terminated file transfers, for example. Identify any such situations you find on the gopher server in your
README or code comments, and how you dealt with each of them – being reasonably liberal in what you
accept and can interpret, or flagging what you cannot accept.
We will test your code against the specified gopher, and check its outputs. If you have any uncertainties
about how to count some things, you can ask your tutor or in the forum. In general, if you explain in your
README how you decide to count things and handle edge-cases, that will be fine.
You can make your crawler's output pretty or add additional information if you'd like, but don't go
overboard. We need to be able to easily see everything that's listed here.
Page 3 of 3
Submission and Assessment
There are a number of existing gopher clients, servers and libraries out there, many of them with source.
While perhaps educational for you, the assessors know they exist and they will be checking your code against
them, and against other submissions from this class.
You need to submit your source code, and a README file (text/word/pdf). Any instructions to run the code,
and any additional comments and insights, please provide those in the README. Your submission must be a
zip file, packaging everything as needed, and submitted through the appropriate link on wattle.
Your code will be assessed on [with marks% available]
1. Output correctness [45%]
o Does the gopher server correctly respond to all of your queries?
o Does your code report the right numbers? (within your interpretation, perhaps)
o Does your code cope well with issues it encounters?
o Does your code provide the running log of requests as above?
2. Performance [10%]
o A great indexer should run as fast as the server allows, and not consume vast amounts of
memory, nor take a very long time. There won’t be too many resources on the server.
3. Code “correctness, clarity, and style” [45%]
o Use of native sockets, writing own gopher requests correctly.
o Documentation, i.e. comments in the code and the README - how easily can somebody else
pick this code up and, say, modify it.
o How easy the code is to run, using a standard desktop environment.
o How does it neatly handle edge-cases, where the server may not be responding perfectly.
During marking your tutor may ask you to explain some particular coding decisions.
Reminder: Wireshark is very helpful to check behaviours of your code by comparing against existing gopher
clients (some are preinstalled in Linux distributions, or are easily added). There are a number of youtube
videos on gopher as well that e.g. show how the clients work. Your tutors can help you with advice (direct or
via the forum) as can fellow students. It’s fine to work in groups, but your submission has to be entirely your
own work.
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- 聚焦3D大赛规则评审会议,青瞳视觉助力构建产教融合沟通桥梁
- 电报/TG全面群发营销平台,Telegram/TG精准群发软件,TG/纸飞机自动化营销工具
- Telegram/TG批量消息发送,电报/TG全球定位采集工具,TG/纸飞机群发引流营销软件
- Instagram自动私信软件,ing接粉神器/ins自动发帖工具
- program代做、代写python设计编程
- Ins一键群发工具,Instagram群发群控工具,让你的营销更高效!
- 转化巅峰 喜悦飞扬 WhatsApp拉群工具为你的销售数字添彩夺目
- 外贸小白晋级手册 WhatsApp拉群工具是我事业腾飞的不二之选
- Instagram群发筛选软件,Ins群发注册工具,助你轻松推广!
- 擘画蓝图 向新而行 英轩集团2024年度商务年会圆满召开
- Telegram营销软件采集器,TG全自动群组采集软件,电报群成员采集利器
- 美国移民EB-5新闻:益博区域中心被起诉
- WhatsApp营销软件,ws群发助手/ws协议号/ws业务咨询大轩
- 成功博主分享 WhatsApp拉群营销工具的魔力 让业务成果显著提升
- Instagram营销软件,ins群发工具/ig采集神器/测试联系大轩
- 跨境推广新选择!Telegram群发云控带您挖掘海外市场的无限商机
- Ins引流工具全新升级,Instagram群发工具助你实现营销突破!
- 没有WhatsApp拉群工具 我曾经的工作就像是踩着泥潭前行 每一步都显得沉重而艰难 每天都需要手动添加联系人 发送消息 效率低下且效果不佳 让我倍感压力
- 业务革新:WhatsApp拉群营销工具是我事业崛起的关键驱动
- 跨境电商群发拉群智能数据解读:WhatsApp代筛料子引领您的数据分析之旅
推荐
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
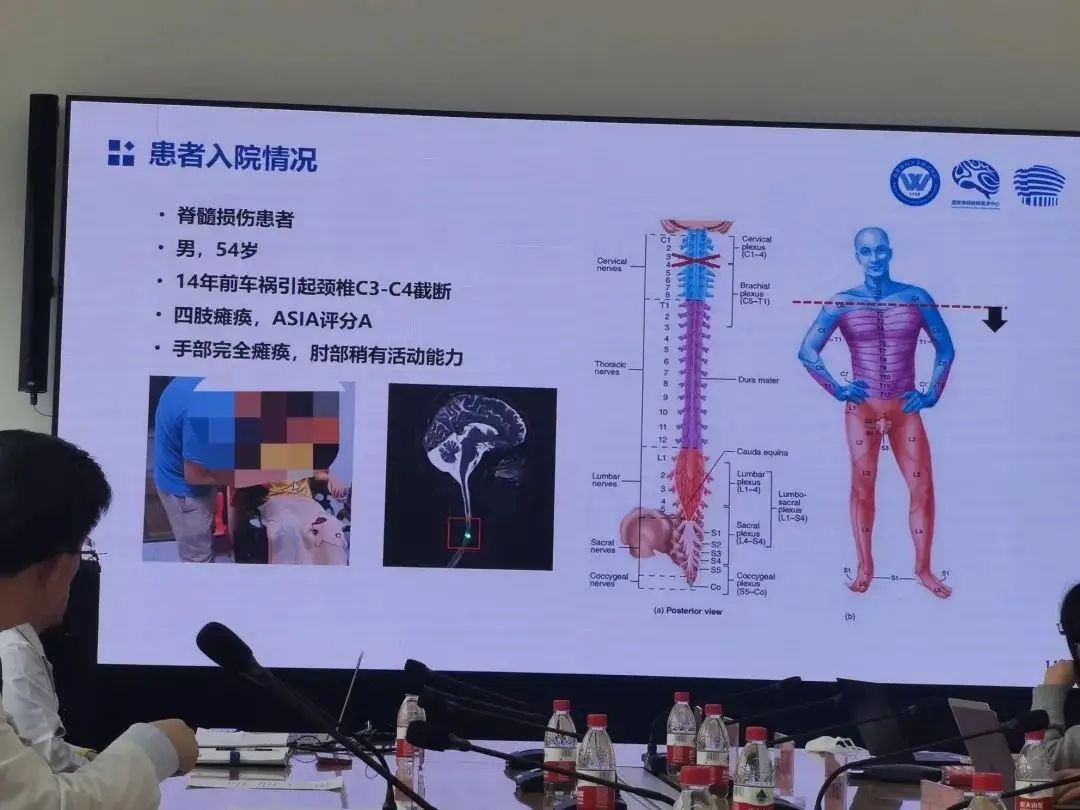 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
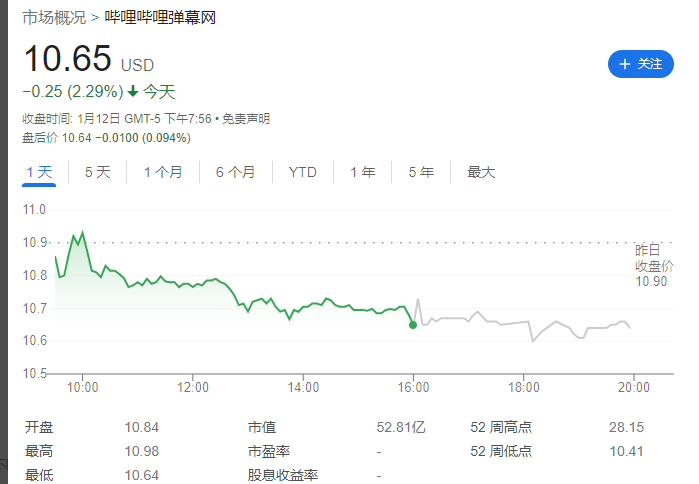 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技