
代写 HW: LLMs!程序、代做 HW: LLMs!
HW: LLMs!
1/16
HW: LLMs, vectors, RAG :)
Summary
In this fi nal HW, you will:
use Weaviate [ ], which is a vector DB - stores data as vectors after vectorizing, and computes a search query by vectorizing it and does
similarity search with existing vectors
crawl the web using a Node package, to compile a 'knowledge base' [to use subsequently (not part of the hw) as input to build a (!)]
using a Python module, perform RAG [retrieval augmentation] on a 'small', locally-hosted LLM [make that an 'S'LM :)]
use to run RAG on their CPU+GPU platform
These are cutting-edge techniques to know, from a POV :) Plus, they are simply, FUN!!
Please make sure you have these installed, before starting: git, Docker, Node, Python (or Conda/Anaconda), [with 'Desktop development with C++'
checked].
Note: you need to do all four, Q1..Q4 (not pick just one!) :)
Q1.
Description
We are going to use vector-based similarity search, to retrieve search results that are not keyword-driven.
The (three) steps we need are really simple:
install Weaviate plus vectorizer via Docker as images, run them as containers
specify a schema for data, upload data/knowledge (in .json format) to have it be vectorized
run a query (which also gets vectorized and then sim-searched), get back results (as JSON)
The following sections describe the above steps.
1. Installing Weaviate and a vectorizer module
After installing Docker, bring it up (eg. on Windows, run Docker Desktop). Then, in your (ana)conda shell, run this docker-compose
command that uses this 'docker-compose.yml' confi g fi le to pull in two images: the 'weaviate' one, and a text2vec transformer
called 't2v-transformers':
docker-compose up -d
https://weaviate.io/
custom GPT
https://lightning.ai
future/career
VS 2022
yaml
HW: LLMs!
2/16
These screenshots show the progress, completion, and subsequently, two containers automatically being started (one for weaviate,
one for t2v-transformers):
HW: LLMs!
3/16
Yeay! Now we have the vectorizer transformer (to convert sentences to vectors), and weaviate (our vector DB search engine)
running! On to data handling :)
2. Loading data to search for
This is the data (knowledge, aka external memory, ie. prompt augmentation source) that we'd like searched, part of which will get
returned to us as results. The data is represented as an array of JSON documents. is our data file, conveniently named
data.json (you can rename it if you like) [you can visualize it better using ] - place it in the 'root' directory of
your webserver (see below). As you can see, each datum/'row'/JSON contains three k:v pairs, with 'Category', 'Question', 'Answer' as
keys - as you might guess, it seems to be in Jeopardy(TM) answer-question (reversed) format :) The fi le is actually called
, I simply made a local copy called data.json.
The overall idea is this: we'd get the 10 documents vectorized, then specify a query word, eg. 'biology', and automagically have that
pull up related docs, eg. the 'DNA' one (even if the search result doesn't contain 'biology' in it)! This is a really useful semantic search
feature where we don't need to specify exact keywords to search for.
Start by installing the weaviate Python client:
pip install weaviate-client
So, how to submit our JSON data, to get it vectorized? Simply use Python script, do:
python weave-loadData.py
Here
https://jsoncrack.com
jeopardy?tiny.json
this
HW: LLMs!
4/16
You will see this:
If you look in the script, you'll see that we are creating a schema - we create a class called 'SimSearch' (you can call it something else
if you like). The data we load into the DB, will be associated with this class (the last line in the script does this via add_data_object()).
NOTE - you NEED to run a local webserver [in a separate ana/conda (or other) shell], eg. via python - it's what will 'serve'
data.json to weaviate :)
Great! Now we have specifi ed our searchable data, which has been fi rst vectorized (by 't2v-transformers'), then stored as vectors (in
weaviate).
Only one thing left: querying!
3. Querying our vectorized data
To query, use this simple shell script called , and run this:
sh weave-doQuery.sh
As you can see in the script, we search for 'physics'-related docs, and sure enough, that's what we get:
'serveit.py'
weave-doQuery.sh
HW: LLMs!
5/16
Why is this exciting? Because the word 'physics' isn't in any of our results!
Now it's your turn:
? fi rst, MODIFY the contents of data.json, to replace the 10 docs in it, with your own data, where you'd replace ("Category","Question","Answer") with
ANYTHING you like, eg. ("Author","Book","Summary"), ("MusicGenre","SongTitle","Artist"), ("School","CourseName","CourseDesc"), etc, etc - HAVE fun
coming up with this! You can certainly add more docs, eg. have 20 of them instead of 10
? next, MODIFY the query keyword(s) in the query .sh fi le - eg. you can query for 'computer science' courses, 'female' singer, 'American' books,
['Indian','Chinese'] food dishes (the query list can contain multiple items), etc. Like in the above screenshot, 'cat' the query, then run it, and get a
screenshot to submit. BE SURE to also modify the data loader .py script, to put in your keys (instead of ("Category","Question","Answer"))
That's it, you're done :) In RL you will have a .json or fi le (or data in other formats) with BILLIONS of items! Later, do feel free to
play with bigger JSON fi les, eg. this Jeopardy JSON fi le :)
FYI/'extras'
Here are two more things you can do, via 'curl':
[you can also do ' ' in your browser]
[you can also do ' ' in your browser]
.csv
200K
http://localhost:8080/v1/meta
http://localhost:8080/v1/schema
HW: LLMs!
6/16
Weaviate has a cloud version too, called - you can try that as an alternative to using the Dockerized version:
Run :)
Also, for fun, see if you can print the raw vectors for the data (the 10 docs)...
More info:
?
?
?
?
Q2.
You are going to run a crawler on a set of pages that you know contain 'good' data - that could be used by an LLM to answer
questions 'intelligently' (ie. not confabulate, ie not 'hallucinate', ie. not make up BS based on its core, general-purpose pre-training!).
The crawled results get conveniently packaged into a single output.json fi le. For this qn, please specify what group of pages you
WCS
this
https://weaviate.io/developers/weaviate/quickstart/end-to-end
https://weaviate.io/developers/weaviate/installation/docker-compose
https://medium.com/semi-technologies/what-weaviate-users-should-know-about-docker-containers-1601c6afa079
https://weaviate.io/developers/weaviate/modules/retriever-vectorizer-modules/text2vec-transformers
HW: LLMs!
7/16
crawled [you can pick any that you like], and, submit your output.json (see below for how to generate it).
Take a look:
You'll need to git-clone 'gpt-crawler' from . Then do 'npm install' to download the needed
Node packages. Then edit confi g.ts [ ] to specify your crawl path,
then simply run the crawler via npm.start! Voila - a resulting output.json, after the crawling is completed.
For this hw, you'll simply submit your output.json - but its true purpose is to serve as input for a cstom GPT :)
From builder.io's GitHub page:
Amazing! You can use this to create all sorts of SMEs [subject matter experts] in the future, by simply scraping existing docs on the
web.
Q3.
For this question, you are going to download a small (3.56G) model (with 7B parameters, compared to GPT-4's 1T for ex!), and use it
along with an external knowledge source (a simple text fi le) vectorized using Chroma (a popular vector DB), and ask questions
https://github.com/BuilderIO/gpt-crawler
https://github.com/BuilderIO/gpt-crawler/blob/main/confi g.ts
HW: LLMs!
8/16
whose answers would be found in the text fi le :) Fun!
git clone this: - and cd into it. You'll see a Python script (app.py) and a requirements.txt fi le.
Install pipenv:
https://github.com/afaqueumer/DocQA
HW: LLMs!
9/16
Install the required components (Chroma, LangChain etc) like so:
Turns out we need a newer version of llama-cpp-python, one of the modules we just installed - so do this:
HW: LLMs!
10/16
Next, let's grab this LLM: https://huggingface.co/TheBloke/Llama-2-7B-GGUF/blob/main/llama-2-7b.Q4_0.gguf - and save it to a
HW: LLMs!
11/16
models/folder inside your DocQA one:
Modify app.py to specify this LLM:
If you are curious about the .gguf format used to specify the LLM, read
Now we have all the pieces! These include the req'd Python modules, the LLM, and an app.py that will launch a UI via . Run
this.
'Streamlit'
HW: LLMs!
12/16
this [pipenv run streamlit run app.py]:
OMG - our chat UI in a browser, via a local webserver [the console prints info about the LLM]:
Now we need a simple text fi le to use for asking questions from (ie. 'external memory' for the LLM). I used
page, to make fi le, for ex.
We are now ready to chat with our doc! Upload the .txt, wait a few minutes for the contents to get vectorized and indexed :) When
https://www.coursera.org/articles/study-habits this
HW: LLMs!
13/16
that is done, ask a question - and get an answer! Like so:
That's quite impressive!
You would need to create a text fi le of your own [you could even type in your own text, about anything!], upload, ask a question,
then get a screenshot of the Q and A. You'd submit the text fi le and the screenshot.
The above is what the new 'magic' (ChatGPT etc) is about!! Later, you can try out , other language tasks, reading
PDF, etc. Such custom 'agents' are sure to become commonplace, serving/dispensing expertise/advice in myriad areas of life.
is more, related to Q3.
Q4.
This is a quick, easy and useful one!
Go to and sign up for a free account. Then read these: and
Browse through their vast collection of 'Studio' templates: - when you create (instantiate) one, you get
your own sandboxed environment [a 'cloud supercomputer'] that runs on lightning.ai's servers. You get unlimited CPU use, and 22
hours of GPU use per month (PLENTY, for beginner projects).
Create this Studio: - you are going to use this
to do RAG using your own PDF :)
Upload (drag and drop) your PDF [can be on ANY topic - coding, cooking, crafting, canoeing, cattle-ranching, catfi shing... (lol!)].
many other models
Here
HW: LLMs!
14/16
Eg. this shows the pdf I uploaded:
Next, edit run.ipynb, modify the 'fi les' variable to point to your pdf:
HW: LLMs!
15/16
Modify the 'query' var, and the 'queries' var, to each contain a QUESTION on which you'd like to do RAG, ie. get the answers from the
pdf you uploaded! THIS is the cool part - to be able to ask questions in natural language, rather than search by keyword, or look up
words in the index [if the pdf has an index].
Read through the notebook to understand what the code does and what the RAG architecture is, then run the code! You'll see the
two answers printed out. Submit screenshots of your pdf fi le upload, the two questions, and the two answers. The answers might
not be what you expected (ie might be imprecise, EVEN though it's RAG!) but that's ok - there are techniques to improve the quality
of the retrieval, you can dive into them later.
After the course, DO make sure to run (almost) all the templates! It's painless (zero installation!), fast (GPU execution!) and
useful/informative (well-documented!). It doesn't get more cutting edge than these, for 'IR'. You can even write and run your own
code in a Studio, and publish it as a template for others to use :)
HW: LLMs!
16/16
Getting help
There is a hw4 'forum' on Piazza, for you to post questions/answers. You can also meet w/the TAs, CPs, or me.
Have fun! This is a really useful piece of tech to know. Vector DBs are sure be used more and more in the near future, as a way to
provide 'infi nite external runtime memory' (augmentation) for pretrained LLMs. Read this too:
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- Instagram营销软件 - ins群发工具/ig营销助手/ins引流神器
- ENGI 1331代做、代写R程序语言
- 前希腊公使见面会把脉希腊移民政策,多房源大优惠多豪礼
- Ins自动私信/强私教程,Instagram营销引流神器全方位解析!
- ws/WhatsApp劫持号购买-ws群发工具-WS精准营销软件
- 代做1CWK100、代写C/C++程序语言
- Instagram营销软件购买指南,Ins自动引流推广采集软件一键搞定!
- Ins协议群发+引流新招!Instagram出海推广软件一键搞定!
- Ins引流营销助手,Instagram打粉工具,助你轻松拓展市场!
- 数字战略巨星 海外高手揭秘 WhatsApp拉群营销工具是业务成功的奥秘所在
- “人工心脏”仅核桃大小,植入男子心尖后重获新生
- 华秋荣膺2023年度中国智能生产杰出应用奖,一站式数智化服务引领电子产业创新升级
- 9月BTE第8届广州国际生物技术大会暨展览会,全媒体聚焦下的高精尖行业盛会
- instagram2024年最强群发营销软件来袭!ins自动推广引流利器
- 智能协议分配,Line协议号注册器助您突破国际市场推广的瓶颈
- COMP 2049 代做代写 c++,java 编程
- InBody发布2024全球人体成分分析报告
- 九章云极DataCanvas公司出席WBBA 2024宽带发展大会
- XCR3064XL-7VQG44I: Pioneering FPGA Solutions for Compact Designs | ChipsX
- Instagram引流神器 - ins采集软件/ig采集助手/ins群发助手
推荐
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
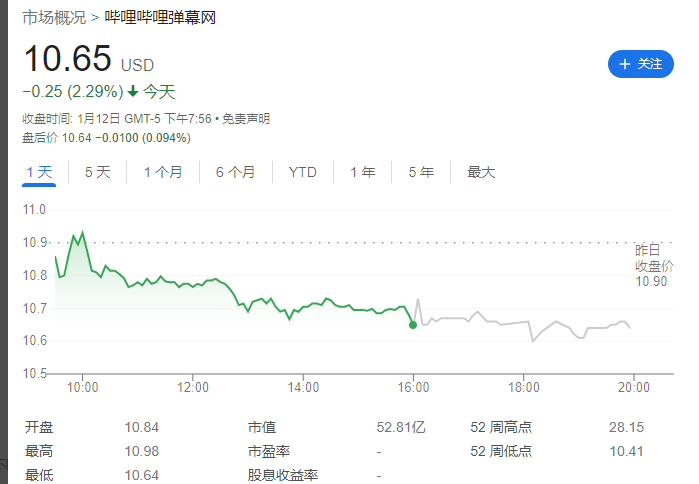 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
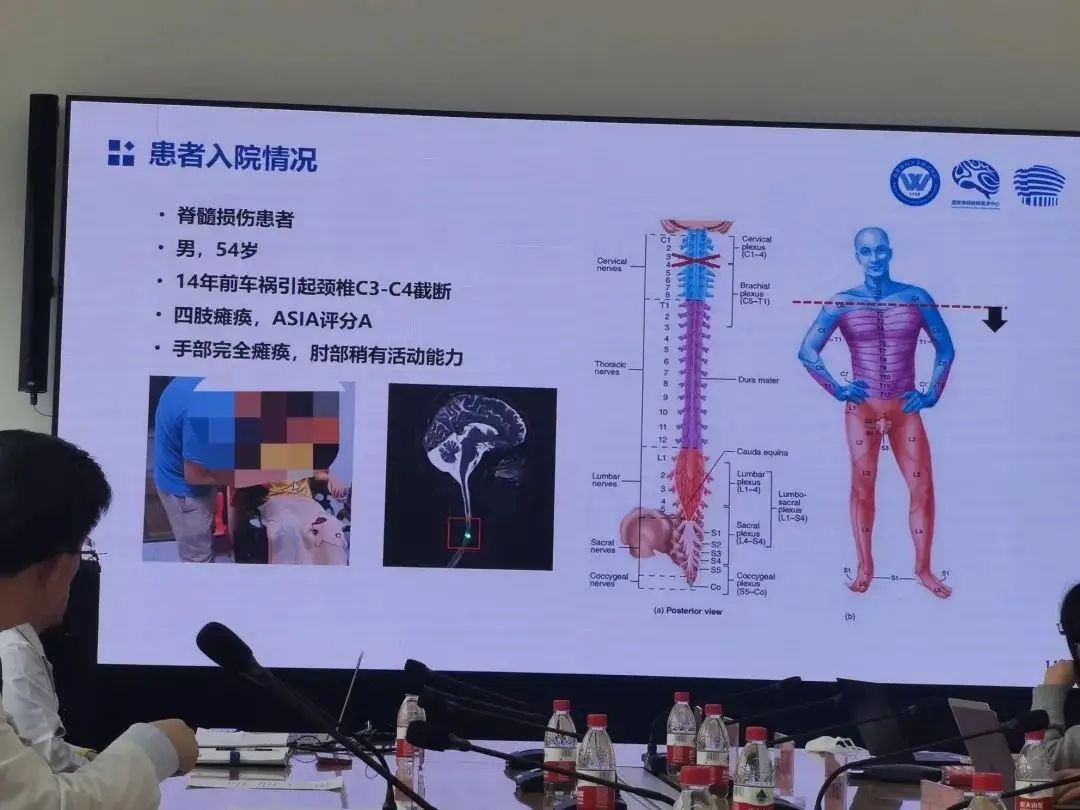 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技