
代写COM6511、代做Python设计程序
COM4511/COM6511 Speech Technology - Practical Exercise -
Keyword Search
Anton Ragni
Note that for any module assignment full marks will only be obtained for outstanding performance that
goes well beyond the questions asked. The marks allocated for each assignment are 20%. The marks will be
assigned according to the following general criteria. For every assignment handed in:
1. Fulfilling the basic requirements (5%)
Full marks will be given to fulfilling the work as described, in source code and results given.
2. Submitting high quality documentation (5%)
Full marks will be given to a write-up that is at the highest standard of technical writing and illustration.
3. Showing good reasoning (5%) Full marks will be given if the experiments and the outcomes are explained to the best standard.
4. Going beyond what was asked (5%)
Full marks will be given for interesting ideas on how to extend work that are well motivated and
described.
1 Background
The aim of this task is to build and investigate the simplest form of a keyword search (KWS) system allowing to find information
in large volumes of spoken data. Figure below shows an example of a typical KWS system which consists of an index and
a search module. The index provides a compact representation of spoken data. Given a set of keywords, the search module
Search Results
Index
Key− words
queries the index to retrieve all possible occurrences ranked according to likelihood. The quality of a KWS is assessed based
on how accurately it can retrieve all true occurrences of keywords.
A number of index representations have been proposed and examined for KWS. Most popular representations are derived
from the output of an automatic speech recognition (ASR) system. Various forms of output have been examined. These differ
in terms of the amount of information retained regarding the content of spoken data. The simplest form is the most likely word
sequence or 1-best. Additional information such as start and end times, and recognition confidence may also be provided for
each word. Given a collection of 1-best sequences, the following index can be constructed
w1 (f1,1, s1,1, e1,1) . . . (f1,n1 , s1,n1 , e1,n1 )
w2 (f1,1, s1,1, e1,1) . . . (f1,n1 , s1,n1 , e1,n1 )
wN (fN,1, sN,1, eN,1) . . . (fN,nN , sN,nN , eN,nN )
(1)
where wi is a word, ni is the number of times word wi occurs, fi,j is a file where word wi occurs for the j-th time, si,j and ei,j
is the start and end time. Searching such index for single word keywords can be as simple as finding the correct row (e.g. k)
and returning all possible tuples (fk,1, sk,1, ek,1), . . ., (fk,nk , sk,nk , ek,nk ).
The search module is expected to retrieve all possible keyword occurrences. If ASR makes no mistakes such module
can be created rather trivially. To account for possible retrieval errors, the search module provides each potential occurrence
with a relevance score. Relevance scores reflect confidence in a given occurrence being relevant. Occurrences with extremely
low relevance scores may be eliminated. If these scores are accurate each eliminated occurrence will decrease the number of
false alarms. If not then the number of misses will increase. What exactly an extremely low score is may not be very easy
to determine. Multiple factors may affect a relevance score: confidence score, duration, word confusability, word context,
keyword length. Therefore, simple relevance scores, such as those based on confidence scores, may have a wide dynamic range
and may be incomparable across different keywords. In order to ensure that relevance scores are comparable among different
keywords they need to be calibrated. A simple calibration scheme is called sum-to-one (STO) normalisation
(2)
where ri,j is an original relevance score for the j-th occurrence of the i-th keyword, γ is a scale enabling to either sharpen or
flatten the distribution of relevance scores. More complex schemes have also been examined. Given a set of occurrences with
associated relevance scores, there are several options available for eliminating spurious occurrences. One popular approach
is thresholding. Given a global or keyword specific threshold any occurrence falling under is eliminated. Simple calibration
schemes such as STO require thresholds to be estimated on a development set and adjusted to different collection sizes. More
complex approaches such as Keyword Specific Thresholding (KST) yield a fixed threshold across different keywords and
collection sizes.
Accuracy of KWS systems can be assessed in multiple ways. Standard approaches include precision (proportion of relevant retrieved occurrences among all retrieved occurrences) and recall (proportion of relevant retrieved occurrences among all
relevant occurrences), mean average precision and term weighted value. A collection of precision and recall values computed
for different thresholds yields a precision-recall (PR) curve. The area under PR curve (AUC) provides a threshold independent summative statistics for comparing different retrieval approaches. The mean average precision (mAP) is another popular,
threshold-independent, precision based metric. Consider a KWS system returning 3 correct and 4 incorrect occurrences arranged according to relevance score as follows: ✓ , ✗ , ✗ , ✓ , ✓ , ✗ , ✗ , where ✓ stands for correct occurrence and ✗ stands
for incorrect occurrence. The average precision at each rank (from 1 to 7) is 1
7 . If the number of true correct
occurrences is 3, the mean average precision for this keyword 0.7. A collection-level mAP can be computed by averaging
keyword specific mAPs. Once a KWS system operates at a reasonable AUC or mAP level it is possible to use term weighted
value (TWV) to assess accuracy of thresholding. The TWV is defined by
(3)
where k ∈ K is a keyword, Pmiss and Pfa are probabilities of miss and false alarm, β is a penalty assigned to false alarms.
These probabilities can be computed by
Pmiss(k, θ) = Nmiss(k, θ)
Ncorrect(k) (4)
Pfa(k, θ) = Nfa(k, θ)
Ntrial(k) (5)
where N<event> is a number of events. The number of trials is given by
Ntrial(k) = T − Ncorrect(k) (6)
where T is the duration of speech in seconds.
2 Objective
Given a collection of 1-bests, write a code that retrieves all possible occurrences of keyword list provided. Describe the search
process including index format, handling of multi-word keywords, criterion for matching, relevance score calibration and
threshold setting methodology. Write a code to assess retrieval performance using reference transcriptions according to AUC,
mAP and TWV criteria using β = 20. Comment on the difference between these criteria including the impact of parameter β.
Start and end times of hypothesised occurrences must be within 0.5 seconds of true occurrences to be considered for matching.
2
3 Marking scheme
Two critical elements are assessed: retrieval (65%) and assessment (35%). Note: Even if you cannot complete this task as a
whole you can certainly provide a description of what you were planning to accomplish.
1. Retrieval
1.1 Index Write a code that can take provided CTM files (and any other file you deem relevant) and create indices in
your own format. For example, if Python language is used then the execution of your code may look like
python index.py dev.ctm dev.index
where dev.ctm is an CTM file and dev.index is an index.
Marks are distributed based on handling of multi-word keywords
• Efficient handling of single-word keywords
• No ability to handle multi-word keywords
• Inefficient ability to handle multi-word keywords
• Or efficient ability to handle multi-word keywords
1.2 Search Write a code that can take the provided keyword file and index file (and any other file you deem relevant)
and produce a list of occurrences for each provided keyword. For example, if Python language is used then the
execution of your code may look like
python search.py dev.index keywords dev.occ
where dev.index is an index, keywords is a list of keywords, dev.occ is a list of occurrences for each
keyword.
Marks are distributed based on handling of multi-word keywords
• Efficient handling of single-word keywords
• No ability to handle multi-word keywords
• Inefficient ability to handle multi-word keywords
• Or efficient ability to handle multi-word keywords
1.3 Description Provide a technical description of the following elements
• Index file format
• Handling multi-word keywords
• Criterion for matching keywords to possible occurrences
• Search process
• Score calibration
• Threshold setting
2. Assessment Write a code that can take the provided keyword file, the list of found keyword occurrences and the corresponding reference transcript file in STM format and compute the metrics described in the Background section. For
instance, if Python language is used then the execution of your code may look like
python <metric>.py keywords dev.occ dev.stm
where <metric> is one of precision-recall, mAP and TWV, keywords is the provided keyword file, dev.occ is the
list of found keyword occurrences and dev.stm is the reference transcript file.
Hint: In order to simplify assessment consider converting reference transcript from STM file format to CTM file format.
Using indexing and search code above obtain a list of true occurrences. The list of found keyword occurrences then can
be assessed more easily by comparing it with the list of true occurrences rather than the reference transcript file in STM
file format.
2.1 Implementation
• AUC Integrate an existing implementation of AUC computation into your code. For example, for Python
language such implementation is available in sklearn package.
• mAP Write your own implementation or integrate any freely available.
3
• TWV Write your own implementation or integrate any freely available.
2.2 Description
• AUC Plot precision-recall curve. Report AUC value . Discuss performance in the high precision and low
recall area. Discuss performance in the high recall and low precision area. Suggest which keyword search
applications might be interested in a good performance specifically in those two areas (either high precision
and low recall, or high recall and low precision).
• mAP Report mAP value. Report mAP value for each keyword length (1-word, 2-words, etc.). Compare and
discuss differences in mAP values.
• TWV Report TWV value. Report TWV value for each keyword length (1-word, 2-word, etc.). Compare and
discuss differences in TWV values. Plot TWV values for a range of threshold values. Report maximum TWV
value or MTWV. Report actual TWV value or ATWV obtained with a method used for threshold selection.
• Comparison Describe the use of AUC, mAP and TWV in the development of your KWS approach. Compare
these metrics and discuss their advantages and disadvantages.
4 Hand-in procedure
All outcomes, however complete, are to be submitted jointly in a form of a package file (zip/tar/gzip) that includes
directories for each task which contain the associated required files. Submission will be performed via MOLE.
5 Resources
Three resources are provided for this task:
• 1-best transcripts in NIST CTM file format (dev.ctm,eval.ctm). The CTM file format consists of multiple records
of the following form
<F> <H> <T> <D> <W> <C>
where <F> is an audio file name, <H> is a channel, <T> is a start time in seconds, <D> is a duration in seconds, <W> is a
word, <C> is a confidence score. Each record corresponds to one recognised word. Any blank lines or lines starting with
;; are ignored. An excerpt from a CTM file is shown below
7654 A 11.34 0.2 YES 0.5
7654 A 12.00 0.34 YOU 0.7
7654 A 13.30 0.5 CAN 0.1
• Reference transcript in NIST STM file format (dev.stm, eval.stm). The STM file format consists of multiple records
of the following form
<F> <H> <S> <T> <E> <L> <W>...<W>
where <S> is a speaker, <E> is an end time, <L> topic, <W>...<W> is a word sequence. Each record corresponds to
one manually transcribed segment of audio file. An excerpt from a STM file is shown below
2345 A 2345-a 0.10 2.03 <soap> uh huh yes i thought
2345 A 2345-b 2.10 3.04 <soap> dog walking is a very
2345 A 2345-a 3.50 4.59 <soap> yes but it’s worth it
Note that exact start and end times for each word are not available. Use uniform segmentation as an approximation. The
duration of speech in dev.stm and eval.stm is estimated to be 57474.2 and 25694.3 seconds.
• Keyword list keywords. Each keyword contains one or more words as shown below
PROUD OF YOURSELF
DON
TWENTY THOUSAND POUNDS
LIB DEM
LIABILITY请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- 你相信吗?只要会说话,人人都会具备程序员的能力
- 网络安全不可或缺:WhatsApp协议号注册器为您的通信保驾护航
- Ins群发脚本助手,Instagram一键群发工具,让你打造营销新格局!
- 优质天然矿泉为健康生活添优选 青啤优活天然矿泉水宝鸡投产
- 营销新时代,选择 WhatsApp群发协议号轻松推广!让您的品牌消息脱颖而出!
- instagram出海营销引流软件,ins强大引流群发私信助手
- 数字秘境的问号:科技魔法师质问,WhatsApp筛选器-WhatsApp营销工具是否是商业科技的迷雾之源
- 数字幻境之夜 科技魔法师的WhatsApp拉群营销工具分享 业务如梦如幻
- 2024“一带一路”瓜菜产业发展大会震撼启动 “新十年 新发展”,共迎国际盛会
- 商务科技狂想曲 科幻魔法师推荐WhatsApp拉群工具 为用户呈现出业务体验的未知魔幻之境
推荐
-
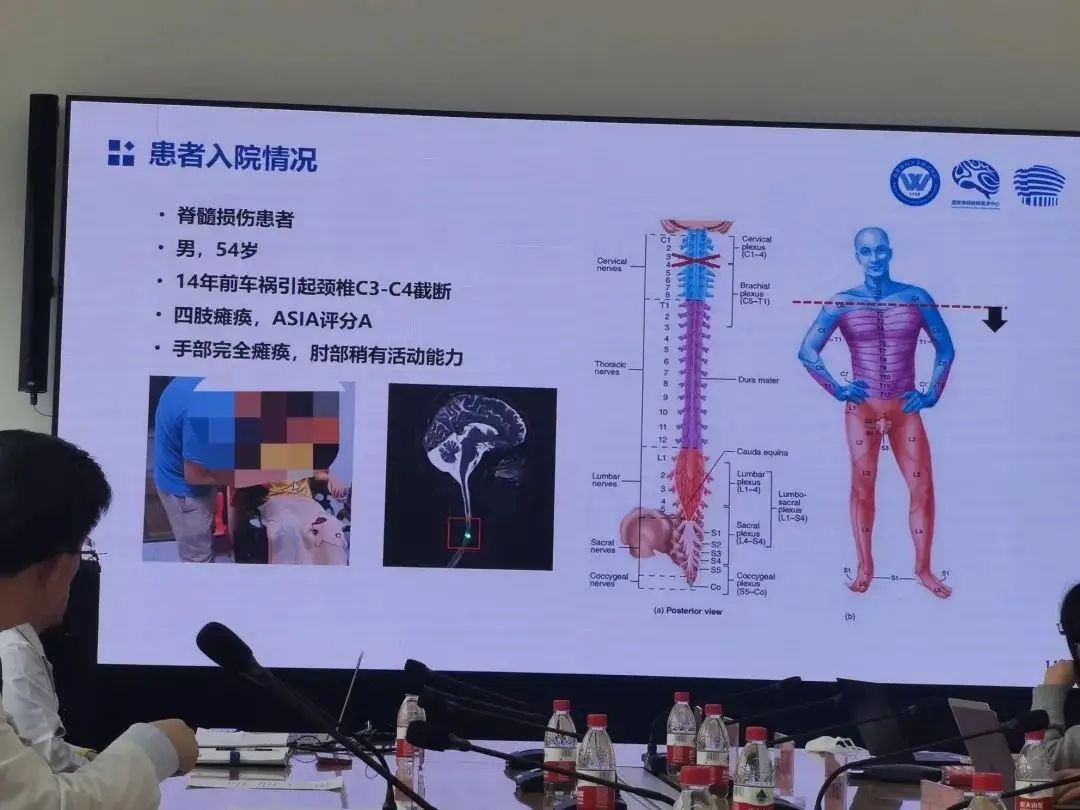 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技