
CISC3025代写、代做Natural Language Processing
University of Macau
CISC3025 - Natural Language Processing
Project#3, 2023/2024
(Due date: 18th April)
Person Name ('Named Entity') Recognition
This is a group project with two students at most. You need to enroll in a group here. In this project,
you will be building a maximum entropy model (MEM) for identifying person names in newswire
texts (Label=PERSON or Label=O). We have provided all of the machinery for training and testing
your MEM, but we have left the feature set woefully inadequate. Your job is to modify the code
for generating features so that it produces a much more sensible, complete, and higher-performing
set of features.
NOTE: In this project, we expect you to design a web application for demonstrating your final
model. You need to design a web page that provides at least such a simple function: 1) User inputs
sentence; 2) Output the named entity recognition results. Of course, more functionalities in your
web application are highly encouraged. For example, you can integrate the previous project’s work,
i.e., text classification, into your project (It would be very cool!).
You NEED to submit:
• Runnable program
o You need to implement a Named Entity Recognition model based on the given starter
codes
• Model file
o Once you have finished the designing of your features and made it functions well, it
will dump a model file (‘model.pkl’) automatically. We will use it to evaluate
your model.
• Web application
o You also need to develop a web application (freestyle, no restriction on programming
languages) to demonstrate your NER model or even more NLP functions.
o Obviously, you need to learn how to call your python project when building the web
application.
• Report
o You should finish a report to introduce your work on this project. Your report should
contain the following content:
§ Introduction;
§ Description of the methods, implementation, and additional consideration to
optimize your model;
§ Evaluations and discussions about your findings;
2
§ Conclusion and future work suggestions.
• Presentation
o You need to give a 8-minute presentation in the class to introduce your work followed
by a 3-minute Q&A section. The content of the presentation may refer to the report.
Starter Code
In the starter code, we have provided you with three simple starter features, but you should be able
to improve substantially on them. We recommend experimenting with orthographic information,
gazetteers, and the surrounding words, and we also encourage you to think beyond these
suggestions.
The file you will be modifying is MEM.py
Adding Features to the Code
You will create the features for the word at the given position, with the given previous label. You
may condition on any word in the sequence (and its relative position), not just the current word
because they are all observed. You may not condition on any labels other than the previous one.
You need to give a unique name for each feature. The system will use this unique name in training
to set the weight for that feature. At the testing time, the system will use the name of this feature
and its weight to make a classification decision.
Types of features to include
Your features should not just be the words themselves. The features can represent any property of
the word, context, or additional knowledge.
For example, the case of a word is a good predictor for a person's name, so you might want to add
a feature to capture whether a given word was lowercase, Titlecase, CamelCase, ALLCAP, etc.
def features(self, words, previous_label, position):
features = {}
""" Baseline Features """
current_word = words[position]
features['has_(%s)' % current_word] = 1
features['prev_label'] = previous_label
if current_word[0].isupper():
features['Titlecase'] = 1
#===== TODO: Add your features here =======#
#...
#=============== TODO: Done ================#
return features
3
Imagine you saw the word “Jenny”. In addition to the feature for the word itself (as above), you
could add a feature to indicate it was in Title case, like:
You might encounter an unknown word in the test set, but if you know it begins with a capital letter
then this might be evidence that helps with the correct prediction.
Choosing the correct features is an important part of natural language processing. It is as much art
as science: some trial and error is inevitable, but you should see your accuracy increasing as you
add new types of features.
The name of a feature is not different from an ID number. You can use assign any name for a
feature as long as it is unique. For example, you can use “case=Title” instead of “Titlecase”.
Running the Program
We have provided you with a training set and a development set. We will be running your programs
on an unseen test set, so you should try to make your features as general as possible. Your goal
should be to increase F1 on the dev set, which is the harmonic mean of the precision and the recall.
You can use three different command flags (‘-t’, ‘-d’, ‘-s’) to train, test, and show respectively.
These flags can be used independently or jointly. If you run the program as it is, you should see the
following training process:
Afterward, it can print out your score on the dev set.
You can also give it an additional flag, -s, and have it show verbose sample results. The first column
is the word, the last two columns are your program's prediction of the word’s probability to be
$ python run.py -d
Testing classifier...
f_score = 0.8715
accuracy = 0.9641
recall = 0.7143
precision = 0.9642
if current_word[0].isupper():
features['Titlecase'] = 1
$ cd NER
$ python run.py -t
Training classifier...
==> Training (5 iterations)
Iteration Log-Likelihood Accuracy
---------------------------------------
1 -0.69315 0.055
2 -0.09383 0.946
3 -0.08134 0.968
4 -0.07136 0.969
Final -0.06330 0.969
4
PERSON or O. The star ‘*’ indicates the gold result. This should help you do error analysis and
properly target your features.
Where to make your changes?
1. Function ‘features()’ in MEM.py
2. You can modify the “Customization” part in run.py in order to debug more efficiently and
properly. It should be noted that your final submitted model should be trained under at least 20
iterations.
3. You may need to add a function “predict_sentence( )” in class MEM( ) to output predictions
and integrate with your web applications.
Changes beyond these, if you choose to make any, should be done with caution.
Grading
The assignment will be graded based on your codes, reports, and most importantly final
presentation.
$ python run.py -s
Words P(PERSON) P(O)
----------------------------------------
EU 0.0544 *0.9456
rejects 0.0286 *0.9714
German 0.0544 *0.9456
call 0.0286 *0.9714
to 0.0284 *0.9716
boycott 0.0286 *0.9714
British 0.0544 *0.9456
lamb 0.0286 *0.9714
. 0.0281 *0.9719
Peter *0.4059 0.5941
Blackburn *0.5057 0.4943
BRUSSELS 0.4977 *0.5023
1996-08-22 0.0286 *0.9714
The 0.0544 *0.9456
European 0.0544 *0.9456
Commission 0.0544 *0.9456
said 0.0258 *0.9742
on 0.0283 *0.9717
Thursday 0.0544 *0.9456
it 0.0286 *0.9714
#====== Customization ======
BETA = 0.5
MAX_ITER = 5 # max training iteration
BOUND = (0, 20) # the desired position bound of samples
#==========================
5
Tips
• Start early! This project may take longer than the previous assignments if you are aiming for
the perfect score.
• Generalize your features. For example, if you're adding the above "case=Title" feature, think
about whether there is any pattern that is not captured by the feature. Would the "case=Title"
feature capture "O'Gorman"?
• When you add a new feature, think about whether it would have a positive or negative weight
for PERSON and O tags (these are the only tags for this assignment).
请加QQ:99515681 邮箱:99515681@qq.com WX:codinghelp

- Ins拉群营销软件,Instagram引流工具,共同打造营销新辉煌!
- 数字狂欢夜WhatsApp拉群工具助我业务飞速发展,客户询盘数暴涨200%
- 揭秘四川点亮饰界建筑装饰材料有限公司全屋整装整体色调搭配相得益彰
- Ins采集工具+私信群发神器,Instagram引流推广双管齐下!
- CE-Channel: Paving the Way for Brand Expansion Abroad with Tailored International Solutions
- Ins/Instagram引流新秘籍,ins群发软件一键解锁精准营销!
- Telegram自动引流营销软件使用教程,TG营销引流工具
- 小土豆们一起穿越南北,品尔滨们YonSuite的魅力烟火
- 破解AI带来的数据存储挑战,西部数据是如何做的?
- 比特币ETF“吸金”41亿美元
- 数字风暴 WhatsApp拉群新功能为何成为市场热门话题 我们的工具给你解密
- 装饰装修网:打造您的梦想家园,让家更有温度
- CHINC2024丨神州医疗重磅发布大模型及一体机,引领医疗AI行业高质量发展
- 法律GPT技术进一步提升律师工作效率,AlphaGPT赋能合同审查
- Instagram新手营销引流怎样做,ins群发私信软件推荐
- 谷器数据入选滨海新区中小企业数字化转型城市试点数字化服务商名单
- Discover Cutting-Edge Innovations at IPC APEX EXPO 2024 with ChipsX!
- WhatsApp群发/ws劫持号/ws协议号/ws拉群/WS全业务咨询
- 担心推广效果不显著 WhatsApp这个工具一键解决你的烦恼 让你的推广事半功倍
- 解锁数字商海的全新纪元:2024年WhatsApp筛选器拉群人才引领行业巅峰
- 未来商战,风起云涌,我一名科技魔法师,手握WhatsApp拉群营销工具,决心打破次元,开创业务新境界。
- WhatsApp拉群奇妙体验:外贸小白的好奇心是如何被这工具激发的?
- 代写CSci 4061 MultiThreaded Image
- instagram多功能自动群发引流营销软件,ins出海营销必备神器
- Ins/Instagram全球引流神器,ins自动爆粉营销新境界!
- 国际战略:专家分享WhatsApp代群发,专业策略引领,推广更富创新力
- ins群发软件好用吗?Instagram独家引流推广群发软件,博主推荐购买!
- Instagram营销群发软件,Ins自动群发助手,助你实现营销梦想!
- CISC3025代写、代做Natural Language Processing
- 取势明道 行稳致远丨直击2024科华合作伙伴大会
推荐
-
 智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
智慧驱动 共创未来| 东芝硬盘创新数据存储技术
为期三天的第五届中国(昆明)南亚社会公共安
科技
-
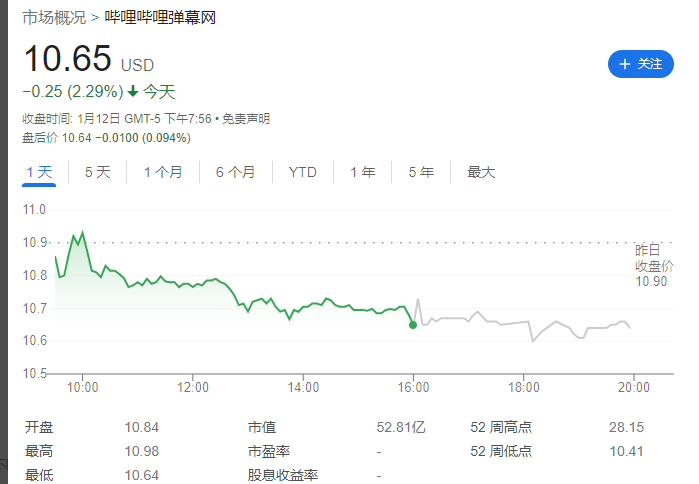 B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
B站更新决策机构名单:共有 29 名掌权管理者,包括陈睿、徐逸、李旎、樊欣等人
1 月 15 日消息,据界面新闻,B站上周发布内部
科技
-
 疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
疫情期间 这个品牌实现了疯狂扩张
记得第一次喝瑞幸,还是2017年底去北京出差的
科技
-
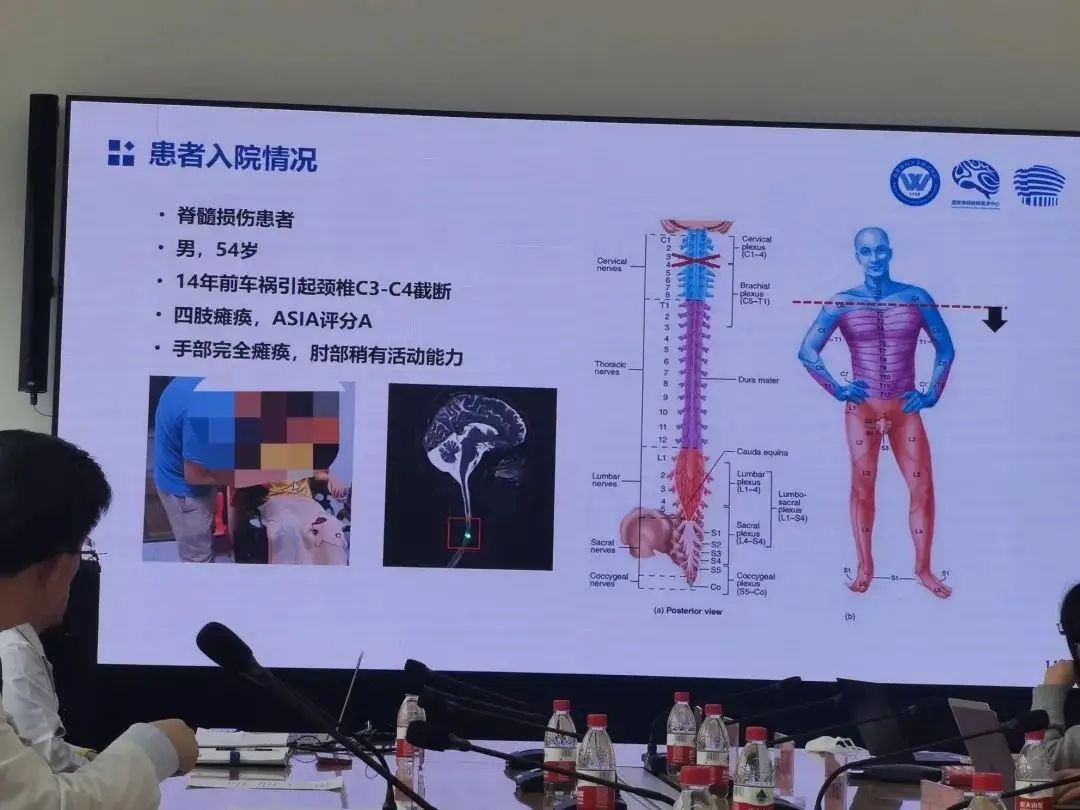 老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
老杨第一次再度抓握住一瓶水,他由此产生了新的憧憬
瘫痪十四年后,老杨第一次再度抓握住一瓶水,他
科技
-
 全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
全力打造中国“创业之都”名片,第十届中国创业者大会将在郑州召开
北京创业科创科技中心主办的第十届中国创业
科技
-
 升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
升级的脉脉,正在以招聘业务铺开商业化版图
长久以来,求职信息流不对称、单向的信息传递
科技
-
 创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
创意驱动增长,Adobe护城河够深吗?
Adobe通过其Creative Cloud订阅捆绑包具有
科技
-
 丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
丰田章男称未来依然需要内燃机 已经启动电动机新项目
尽管电动车在全球范围内持续崛起,但丰田章男
科技
-
 如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
如何经营一家好企业,需要具备什么要素特点
我们大多数人刚开始创办一家企业都遇到经营
科技
-
 苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技
苹果罕见大降价,华为的压力给到了?
1、苹果官网罕见大降价冲上热搜。原因是苹
科技