
谷歌Gemini 1.5深夜爆炸上线,史诗级多模态硬刚GPT-5!最强MoE首破100万极限上下文纪录
资讯
2024-02-16 ·
刚刚,我们经历了LLM划时代的一夜。谷歌又在深夜发炸弹,Gemini Ultra发布还没几天,Gemini 1.5就来了。卯足劲和OpenAI微软一较高下的谷歌,开始进入了高产模式。
自家最强的Gemini 1.0 Ultra才发布没几天,谷歌又放大招了。
就在刚刚,谷歌DeepMind首席科学家Jeff Dean,以及联创兼CEO的Demis Hassabis激动地宣布了最新一代多模态大模型——Gemini 1.5系列的诞生。
其中,最高可支持10,000K token超长上下文的Gemini 1.5 Pro,也是谷歌最强的MoE大模型。
不难想象,在百万级token上下文的加持下,我们可以更加轻易地与数十万字的超长文档、拥有数百个文件的数十万行代码库、一部完整的电影等等进行交互。


同时,为了介绍这款划时代的模型,谷歌还发布了长达58页的技术报告。

论文地址:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
毫不夸张地说,大语言模型领域从此将进入一个全新的时代!
1,000,000 token超超超长上下文,全面碾压GPT-4 Turbo
在上下文窗口方面,此前的SOTA模型已经「卷」到了200K token(20万)。
如今,谷歌成功将这个数字大幅提升——能够稳定处理高达100万token(极限为1000万token),创下了最长上下文窗口的纪录。

- 茅子俊《仙剑四》演技备受好评 表演细腻圈粉无数
- Instagram群发筛选软件,Ins群发注册工具,助你轻松推广!
- 夏目当科技株式会社宣布与腾讯天美工作室群(TiMi Studio Group)合作
- IVA艺术 | 气度、地缘与写意性——罗江绘画的审美索迹
- PUMA任命Julie Legrand担任全球品牌战略领导
- 万代兰,一个致力于为中医药现代化代言的民族品牌
- AutoAI2024第七届自动驾驶及智能座舱中国峰会开放注册
- 2024“蓉漂杯”电子信息产业链主企业命题揭榜赛顺利举行!
- Ververica在新加坡的阿里云人工智能与大数据峰会上展示了数据流处理
- 奥迪威智能家电应用系列新品将强势登陆AWE博览会!
- 从一场交付,读懂招商蛇口与西安的“十年之约”
- nCino to Acquire DocFox
- 国内拥有“智慧停车管理系统”专利最多的企业是艾润停车王
- 桥彼道完成 B2 轮融资,为市场扩张及产品创新注入动力
- 燕之屋浓鲜燕窝
- 【福州爱尔】泡温泉一时爽,过后眼睛又红又肿
- 水龙头寿命试验机:保障产品质量,提升市场竞争力
- 男子“机闹”后航班取消,同机旅客准备集体起诉
- 高端转型迷茫不只格力有
- Tecnotree与Umniah达成数百万美元交易, 领衔Sensa AIML嵌入式BSS转型
- 2024年健康减肥的新选择:敦集十日瘦
- 质之水:科技激活每一滴,驱动功能性饮水新潮流
- 芬兰儿童权利非政府组织Protect Children的最新研究揭示了犯罪分子如何利用技术平台对儿童进行在线性虐待
- At the Yacht Club de Monaco the Pink Wave Sailing Team sends their message for the International Wom
- 中国当代著名书法家郎百忠先生荣获《中国十大杰出书法家》第一名
- 临商银行金雀山支行开展断卡行动
- 曾黎米兰时装周看秀 造型惊艳状态超绝 手写签名红包送给留学生
- Anker安克联手《温暖的客栈》,种草明星同款三合一能量棒
- SmartThings智能互联服务全新升级! SmartThings平台现支持Yeelight易来设备
- 上饶弋阳瓷砖壁画瓷砖标识牌定制-美佳壁画
推荐
-
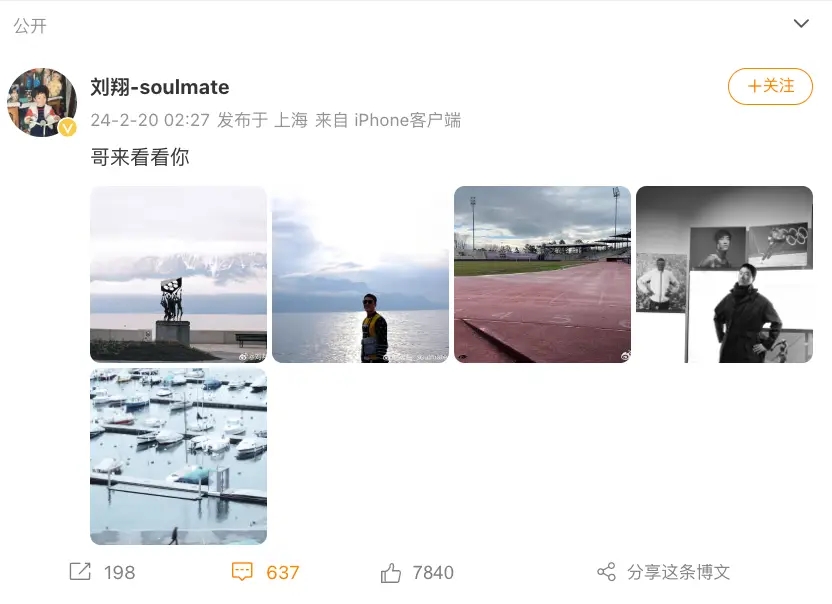 奥运冠军刘翔更新社交账号晒出近照 时隔473天更新动态!
2月20日凌晨2点,奥运冠军刘翔更新社交账号晒
资讯
奥运冠军刘翔更新社交账号晒出近照 时隔473天更新动态!
2月20日凌晨2点,奥运冠军刘翔更新社交账号晒
资讯
-
 男子“机闹”后航班取消,同机旅客准备集体起诉
1月4日,一男子大闹飞机致航班取消的新闻登上
资讯
男子“机闹”后航班取消,同机旅客准备集体起诉
1月4日,一男子大闹飞机致航班取消的新闻登上
资讯
-
 抖音直播“新红人”进攻本地生活领域
不难看出,抖音本地生活正借由直播向本地生活
资讯
抖音直播“新红人”进攻本地生活领域
不难看出,抖音本地生活正借由直播向本地生活
资讯
-
 新增供热能力3200万平方米 新疆最大热电联产项目开工
昨天(26日),新疆最大的热电联产项目—&md
资讯
新增供热能力3200万平方米 新疆最大热电联产项目开工
昨天(26日),新疆最大的热电联产项目—&md
资讯
-
 海南大学生返校机票贵 有什么好的解决办法吗?
近日,有网友在“人民网领导留言板&rdqu
资讯
海南大学生返校机票贵 有什么好的解决办法吗?
近日,有网友在“人民网领导留言板&rdqu
资讯
-
 中国减排方案比西方更有优势
如今,人为造成的全球变暖是每个人都关注的问
资讯
中国减排方案比西方更有优势
如今,人为造成的全球变暖是每个人都关注的问
资讯
-
 看新东方创始人俞敏洪如何回应董宇辉新号分流的?
(来源:中国证券报)
东方甄选净利润大幅下滑
资讯
看新东方创始人俞敏洪如何回应董宇辉新号分流的?
(来源:中国证券报)
东方甄选净利润大幅下滑
资讯
-
 国足13次出战亚洲杯首次小组赛0进球
北京时间1月23日消息,2023亚洲杯小组
资讯
国足13次出战亚洲杯首次小组赛0进球
北京时间1月23日消息,2023亚洲杯小组
资讯
-
 中央气象台连发四则气象灾害预警
暴雪橙色预警+冰冻橙色预警+大雾黄色预警+
资讯
中央气象台连发四则气象灾害预警
暴雪橙色预警+冰冻橙色预警+大雾黄色预警+
资讯
-
 一个“江浙沪人家的孩子已经不卷学习了”的新闻引发议论纷纷
星标★
来源:桌子的生活观(ID:zzdshg)
没
资讯
一个“江浙沪人家的孩子已经不卷学习了”的新闻引发议论纷纷
星标★
来源:桌子的生活观(ID:zzdshg)
没
资讯